过去近一年主要的工作任务是基于ABAC授权策略的IAM系统开发,终于发布上线。
这是一个从0到1的经历过程,本文主要是个人对基于ABAC授权策略的IAM系统开发的流程和关键点的观点总结。
IAM系统中的权限策略模型
Identity and Access Management (IAM) 是一种 Web 服务,可以帮助您安全地控制对 AWS 资源的访问。您可以使用 IAM 控制对哪个用户进行身份验证 (登录) 和授权 (具有权限) 以使用资源。
在权限策略控制的设计中,更广为人知的是: RBAC。
RBAC认为权限授权的过程可以抽象地概括为:Who是否可以对What进行How的访问操作,并对这个逻辑表达式进行判断是否为True的求解过程,也即是将权限问题转换为What、How的问题,Who、What、How构成了访问权限三元组,也就是三个主要元素: 用户、角色和权限。
另一种模型是: ABAC。基于属性的访问控制(ABAC)是一种授权策略,基于属性来定义权限。
RBAC模型的简单明了和更贴近现实世界的逻辑场景能够满足大部分权限控制管理的需求。
但是由于原有系统的RBAC模型已经无法满足我们实际产品中复杂和灵活的权限控制需求,所以我们决定开始了基于ABAC模型开发IAM系统。
之后文章讲的IAM都是指基于ABAC授权策略的IAM系统。
AWS IAM是最好的产品资料
AWS IAM产品应该是IAM产品中的业界标杆。
- AWS足够复杂,有不同的登入方式,权限获取方式,权限控制的场景
- AWS IAM产品文档较完整
不了解基于ABAC模型的IAM具体是怎样的,对我们来说这是新的概念和知识。在对友商和业界标杆AWS IAM等产品进行调研和文档查阅后,对ABAC模型有了一定的认知。了解了IAM中有哪些重要的概念,能够应用于哪些场景,以及关键的要素和功能实现有可能的难点。
###最简单的IAM系统
从认知到实现还有很长的一段路程。即使调研了主流友商的IAM产品,但是无法知道他们的底层设计是如何实现的。所以决定先实现一个最简单的IAM系统。
最简单的IAM系统应该包括:
- 管理模块
- 鉴权模块
管理模块:管理IAM中需要的数据和实体,比如:用户管理、组管理、角色管理、策略管理。
鉴权模块:基于ABAC模型的策略鉴权方式。
策略是一个重要的元素。
策略是 IAM 中的对象;在与身份或资源相关联时,策略定义它们的权限。在委托人使用 IAM 实体(如用户或角色)发出请求时, 服务将评估这些策略。策略中的权限确定是允许还是拒绝请求。
一个策略大概是长这样:
{
"Version": "2012-10-17",
"Statement": {
"Effect": "Allow",
"Action": "dynamodb:*",
"Resource": "arn:aws:dynamodb:us-east-2:123456789012:table/Books",
"Condition":""
}
}
策略其实就是我们制定的权限规则。策略与某个实体(例如用户)绑定在一起,当用户进行访问请求时,会检查拥有的策略进行匹配,匹配成功,则响应对应的操作,匹配失败则说明没有权限。
在RBAC中的鉴权流程是: 角色是否有权限。
在IAM ABAC中的鉴权流程是:请求是否匹配了策略。
由于策略的制定是非常灵活的,也就是ABAC的权限模型比RBAC权限模型更能满足灵活和复杂的场景的原因。
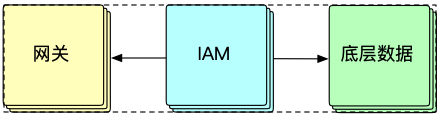
这个最简单的IAM系统是将两个模块需要的接口设计好,开发完成,通过手动组装参数(Postman)调用接口能够调通。对于整个IAM系统来说,只是完成了其中的一环,还有其他重要的部分:网关和底层数据系统。
###重要的一环:网关
在网关进行鉴权是大部分系统的选择方案。底层鉴权模式改了,原来存在的各种鉴权类型都需要能够兼容。所以,网关鉴权的改造是重要的一环。
当请求到达网关,网关需要做的事情是根据请求的参数,能够得到对应的实体(比如用户),将鉴权需要的所有信息准备好,然后调用IAM服务的接口,进行权限校验。如果成功,则将请求转发到具体业务,失败,则返回没有操作权限错误。
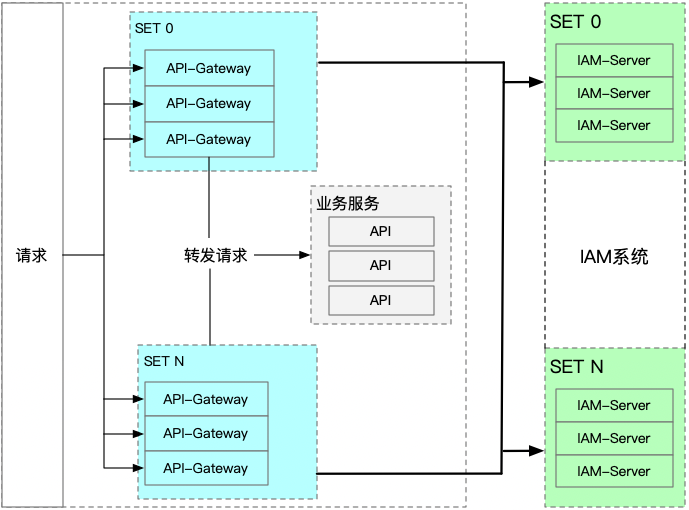
###底层数据系统
底层数据系统一般包含这些:
- 产品数据系统
- 接口数据系统
- 资源数据系统
- 属性数据系统

一个功能强大的IAM系统需要这些底层数据系统的支持。IAM系统中的关键对象是策略,它决定着ABAC的鉴权方式。而策略中的组成对象Action、Resource和Condition中的定义,就是来源于产品、接口、资源、属性,下面具体讲解。
一个简单的鉴权例子
可以这样理解:用户进行产品操作是通过调用接口的方式操作某资源进行增、删、改、查。
先一起了解一下在IAM服务是如何鉴权的。
假设网关准备好了参数传递给了IAM服务,IAM服务进行:
- 查找对应的策略
- 匹配Action
- 匹配Resource
- 匹配Condition(如果有配置)
如下图:
我们发起了一个接口请求,参数是这样的:
{
"Action": "UpdateUFileName",
"Name": "aaabbb",
"ObjectID": 1
}
在鉴权的时候,假设查找到了唯一的对应的策略A。就需要将请求参数中的Action和策略A中的Action进行匹配(这里请求没有传Resource参数,所以不用匹配),如果匹配成功,就会执行Effect定义的相应Allow允许或Deny拒绝操作,如果没有匹配成功也是拒绝。
如果只是”完全相等”的匹配,对于底层数据的支持要求很低,但这种匹配是无法实现灵活的功能的。
如果需要灵活方式的匹配,对于底层数据的支持要求很高。
在AWS 的策略定义中是支持通配符匹配的,比如: "Action": "dynamodb:*"。
接口设计,资源设计没有任何制定的规范规则,如何在策略定义中支持通配符匹配呢?
策略的定义是可以实现很灵活的匹配以满足实际需求,然而灵活并非无规则、无序。
假设我们这样规范一个接口的名称: 操作+产品+其他。拆解一下UpdateUFileName接口
- 操作:Update
- 产品:UFile
- 其他:Name
通过接口名称就能知道是什么操作了具体哪款产品。在策略中不就可以制定通配符匹配的规则了嘛。
{
"Version": "2012-10-17",
"Statement": {
"Effect": "Allow",
"Action": "UFile:Update*"
}
}
策略表示:UFile 产品的所有更新接口操作都允许。
同理Resource需要资源数据系统的支持。
IAM权限系统需要产品数据系统、接口数据系统、资源数据系统、属性数据系统的支持(根据自身匹配业务的需求来确定需要哪些底层数据系统的支持)。如果没有,强烈建议先进行底层数据系统的设计。
IAM系统涉及的系统架构
###关于策略匹配算法
我们知道,关于匹配算法,正则匹配会是第一个想到的方案,正则匹配的功能太强大了。但是,正则匹配功能强大,匹配性能很可能较低。由于策略的匹配是很频繁的操作,对性能有较高要求。我们找到了替代正则匹配的方案,通配符匹配的方式,能够满足策略的匹配需求。下面是一个benchmark:
package benchmark
import (
"path/filepath"
"regexp"
"testing"
"github.com/gobwas/glob"
)
const (
pattern_prefix = "abc*"
regexp_prefix = `^abc.*$`
pattern_suffix = "*def"
regexp_suffix = `^.*def$`
pattern_prefix_suffix = "ab*ef"
regexp_prefix_suffix = `^ab.*ef$`
fixture_prefix_suffix_match = "abcdef"
fixture_prefix_suffix_mismatch = "af"
)
func BenchmarkPrefixRegexpMatch(b *testing.B) {
m := regexp.MustCompile("^aaa:bbb:.*:cccccc:myphotos/hangzhou/2015/.*$")
f := []byte("aaa:bbb:b:cccccc:myphotos/hangzhou/2015/aaa")
for i := 0; i < b.N; i++ {
_ = m.Match(f)
}
}
func BenchmarkPrefixFilepathMatch(b *testing.B) {
for i := 0; i < b.N; i++ {
_, _ = filepath.Match("aaa:bbb:*:cccccc:myphotos/hangzhou/2015/*", "aaa:bbb:b:cccccc:myphotos/hangzhou/2015/aaa")
}
}
func BenchmarkPrefixGlobMatch(b *testing.B) {
var g glob.Glob
// create simple glob
g = glob.MustCompile("aaa:bbb:*:cccccc:myphotos/hangzhou/2015/*")
for i := 0; i < b.N; i++ {
g.Match("aaa:bbb:b:cccccc:myphotos/hangzhou/2015/aaa") // true
}
}
func BenchmarkSuffixRegexpMatch(b *testing.B) {
m := regexp.MustCompile("^.*:aaa:abcabcabc")
f := []byte("123:aaa:abcabcabc")
for i := 0; i < b.N; i++ {
_ = m.Match(f)
}
}
func BenchmarkSuffixFilepathMatch(b *testing.B) {
for i := 0; i < b.N; i++ {
_, _ = filepath.Match("*:aaa:abcabcabc", "123:aaa:abcabcabc")
}
}
func BenchmarkSuffixGlobMatch(b *testing.B) {
var g glob.Glob
// create simple glob
g = glob.MustCompile("*:aaa:abcabcabc")
for i := 0; i < b.N; i++ {
g.Match("123:aaa:abcabcabc") // true
}
}
func BenchmarkPrefixSuffixRegexpMatch(b *testing.B) {
m := regexp.MustCompile(regexp_prefix_suffix)
f := []byte(fixture_prefix_suffix_match)
b.ResetTimer()
for i := 0; i < b.N; i++ {
_ = m.Match(f)
}
}
func BenchmarkPrefixSuffixFilepathMatch(b *testing.B) {
for i := 0; i < b.N; i++ {
_, _ = filepath.Match(pattern_prefix_suffix, fixture_prefix_suffix_match)
}
}
func BenchmarkPrefixSuffixGlobMatch(b *testing.B) {
var g glob.Glob
// create simple glob
g = glob.MustCompile(pattern_prefix_suffix)
for i := 0; i < b.N; i++ {
g.Match(fixture_prefix_suffix_match) // true
}
}
// go test -bench=. benchmark_test.go
/*
goos: darwin
goarch: amd64
BenchmarkPrefixRegexpMatch-4 695192 2333 ns/op
BenchmarkPrefixFilepathMatch-4 3774104 404 ns/op
BenchmarkPrefixGlobMatch-4 20142326 71.3 ns/op
BenchmarkSuffixRegexpMatch-4 1470373 713 ns/op
BenchmarkSuffixFilepathMatch-4 10244230 103 ns/op
BenchmarkSuffixGlobMatch-4 147599737 7.88 ns/op
BenchmarkPrefixSuffixRegexpMatch-4 4915987 228 ns/op
BenchmarkPrefixSuffixFilepathMatch-4 19263058 61.9 ns/op
BenchmarkPrefixSuffixGlobMatch-4 90101554 13.0 ns/op
PASS
ok command-line-arguments 13.843s
*/
上述是一个通配符匹配库glob和正则匹配的一个benchmark,可以看到匹配性能提升了20倍以上
产品体验
IAM产品的使用学习成本是有点高的,主要是在对策略的创建方面。因为策略匹配的灵活性,使用者可以组合出各种各样的权限。这样也就会产生一个问题:策略实现权限的重复和冲突。
我们的方案是:尽量在用户体验上做更多的优化,简化用户的操作,用尽可能简单的策略和组织来实现用户的需求。
经过灰度上线部分用户后,得到了一些反馈。和预期相符,主要分为两种:
- 习惯原先RABC权限模型管理方式。
- 新的IAM系统学习成本高,对策略的灵活定义不熟悉。
针对这两种反馈,下面介绍两种使用新IAM系统的方式:
像RABC权限模型一样管理权限
-
创建一个用户组
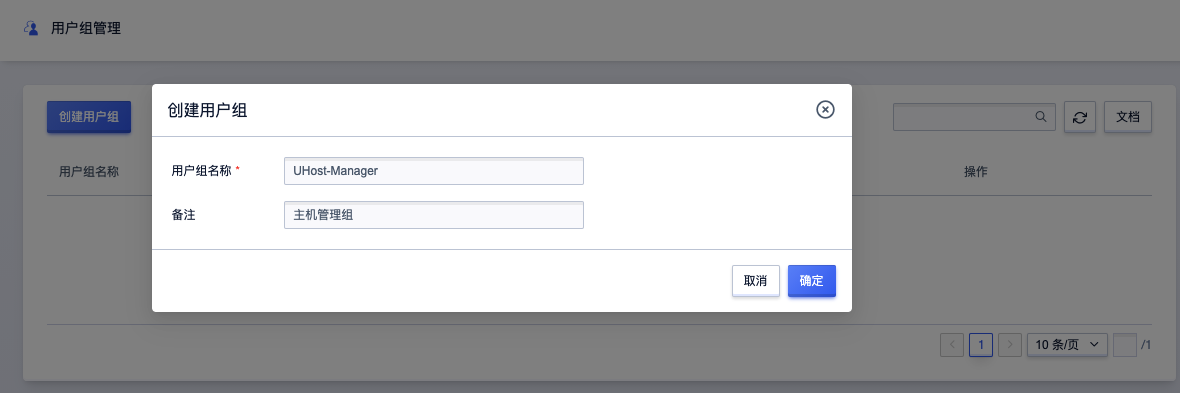
-
添加权限:在选择的应用项目下,给
UHost-Manager组添加云主机(UHost)管理员权限,UHost-Manager组就拥有对主机进行所有操作权限。(分配什么权限可以根据需要选择)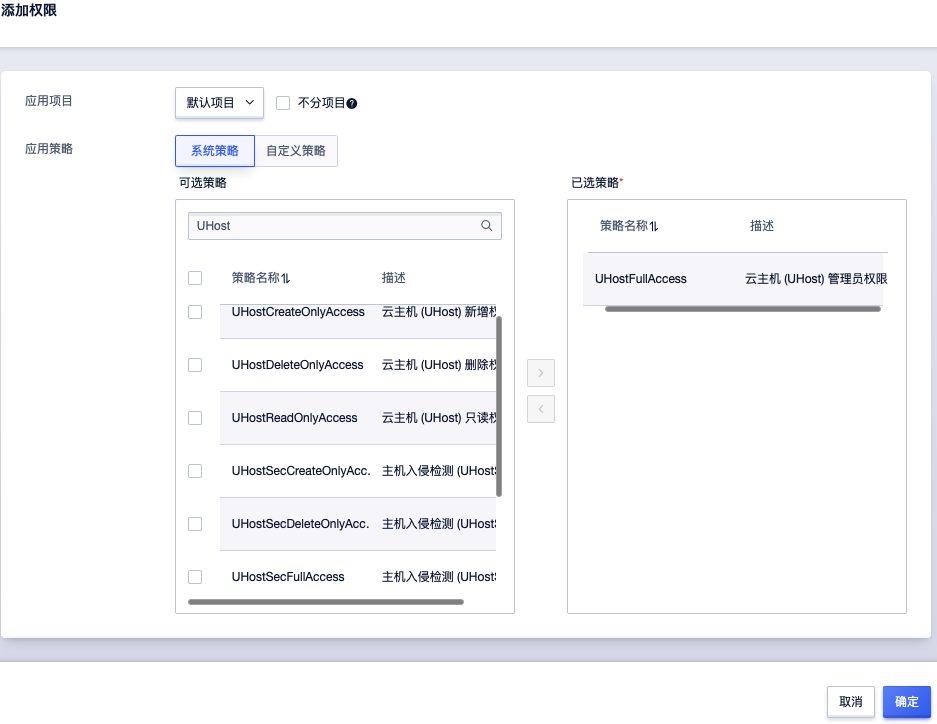
-
添加成员:将用户名为
name-ghfaq69y添加到UHost-Manager组
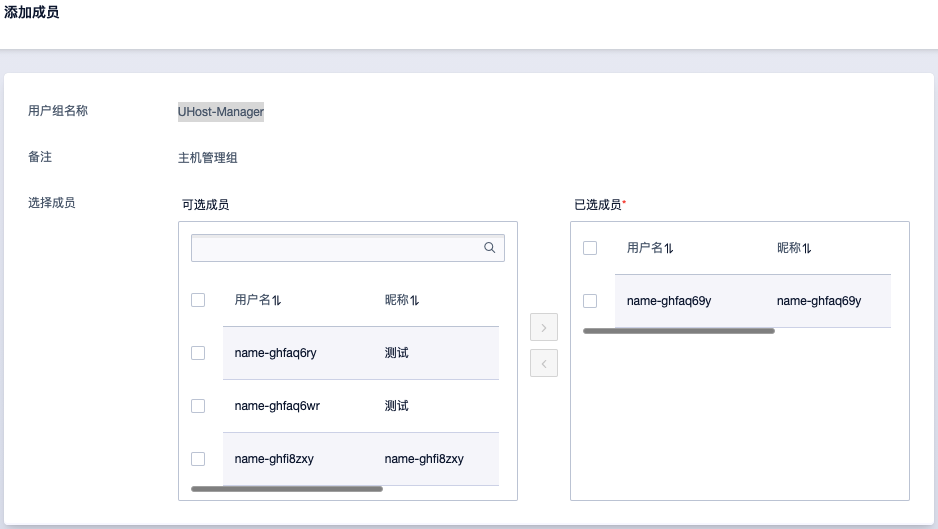
这样操作后,name-ghfaq69y用户就能对主机进行操作了。和原来分配角色是类似的,把组当成角色来使用。
###步入ABAC权限模型,尝试灵活的策略定义
下面来看看更高阶的权限控制:
- 创建自定义策略,按照下面进行配置
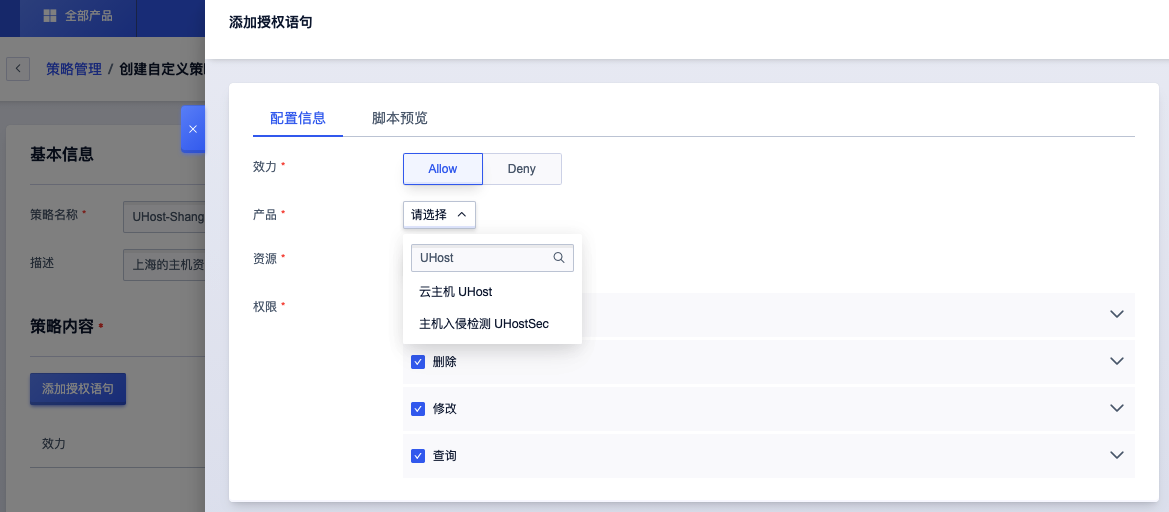
-
知道上海主机的资源ID名称,填入特定资源进行配置,点击确定,完成自定义策略创建
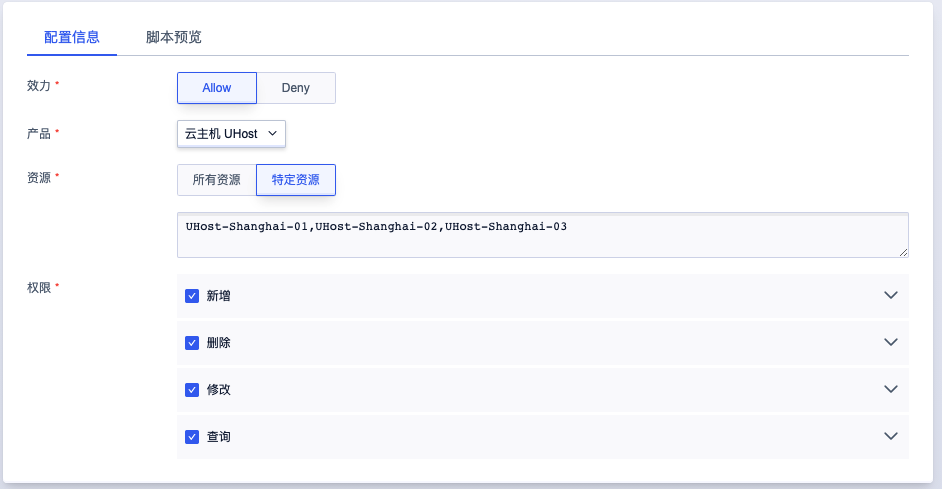
-
添加权限:到用户管理=>选择某个用户(这里选择
name-ghfaq69y)=>添加权限。在选择的应用项目下=>选择自定义策略=>选择刚才创建的UHost-Shanghai策略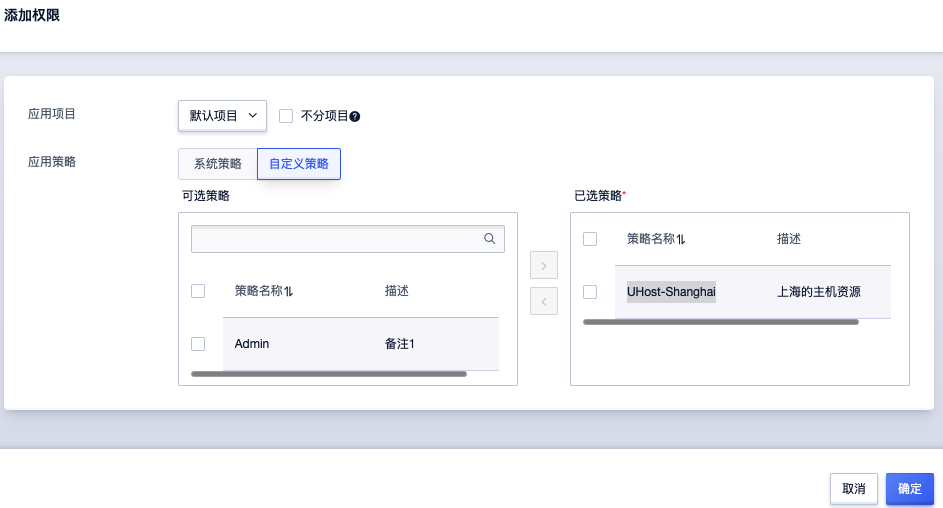
点击确认后,
name-ghfaq69y用户能对刚才配置的三个上海主机资源进行增、删、改、查操作,而对北京或其他地域的主机资源没有操作权限。
对比一下这两种使用方式,第二种使用方式是新IAM系统更强的权限控制功能。
扩展
思考非中心化的鉴权方式。
中心化的鉴权方式:网关与鉴权服务集群通信后,再将请求转到具体业务方服务。如果这个鉴权服务集群挂了,整个业务就不通了。
非中心化的鉴权方式:以SDK的方式,在每个业务方进行鉴权。这样,各个业务方服务是互不影响的。但是使用SDK的方式,会带来SDK管理使用的问题,比如:不同业务方技术栈的不同,使得需要提供多种技术语言的SDK实现。SDK升级的时候,需要考虑老版本,以及每个技术语言的SDK都需要升级,在大版本升级无法兼容旧版本的情况,还需要协调所有业务方都升级,这边也是一个不小的维护工作量。
目前个人觉得,中心化的集群方式对于服务端开发来说是更合理的方式。如果请求量逐渐增加,系统性能瓶颈出现,那么选择增加服务器和集中优化系统性能让系统保持稳定。
区块链技术能否应用其中?
优化
- 对资源和属性匹配时O(n^2)的时间复杂度优化
出现O(n^2)的时间复杂度,是因为带*的通配符匹配的情况,只能一个一个拿出来匹配,如果是精确值的匹配,可以借助map作为内存缓存的方式。所以,将策略中的资源数据分成两类,一类是精确值,一类是通配符匹配。精确值用map存储,这样能减少时间复杂度n的数量,从而达到优化
- 使用并发的方式进行匹配。根据resource或属性的数量,创建一定的goroutine并发进行匹配操作。resource或属性的之间并没有优先级或上下文的关系,所以可以进行并发操作。要注意的是,满足条件的时候就可以返回,并且要发消息告诉其他goroutine可以停止操作,使用context或者用统一的stopCha channel可以达到这样的效果
参考链接:
https://github.com/gobwas/glob
https://tldp.org/LDP/GNU-Linux-Tools-Summary/html/x11655.htm