etcd集群启动方式
$ etcd -name infra0 -initial-advertise-peer-urls http://10.0.1.10:2380 \
-listen-peer-urls http://10.0.1.10:2380 \
-initial-cluster-token etcd-cluster-1 \
-initial-cluster infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380,infra2=http://10.0.1.12:2380 \
-initial-cluster-state new
$ etcd -name infra1 -initial-advertise-peer-urls http://10.0.1.11:2380 \
-listen-peer-urls http://10.0.1.11:2380 \
-initial-cluster-token etcd-cluster-1 \
-initial-cluster infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380,infra2=http://10.0.1.12:2380 \
-initial-cluster-state new
$ etcd -name infra2 -initial-advertise-peer-urls http://10.0.1.12:2380 \
-listen-peer-urls http://10.0.1.12:2380 \
-initial-cluster-token etcd-cluster-1 \
-initial-cluster infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380,infra2=http://10.0.1.12:2380 \
-initial-cluster-state new
SQL JOIN 中 on 与 where 的区别
- left join : 左连接,返回左表中所有的记录以及右表中连接字段相等的记录。
- right join : 右连接,返回右表中所有的记录以及左表中连接字段相等的记录。
- inner join : 内连接,又叫等值连接,只返回两个表中连接字段相等的行。
- full join : 外连接,返回两个表中的行:left join + right join。
- cross join : 结果是笛卡尔积,就是第一个表的行数乘以第二个表的行数。
关键字 on 数据库在通过连接两张或多张表来返回记录时,都会生成一张中间的临时表,然后再将这张临时表返回给用户。 在使用 left jion 时,on 和 where 条件的区别如下:
- 1、 on 条件是在生成临时表时使用的条件,它不管 on 中的条件是否为真,都会返回左边表中的记录。
- 2、where 条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有 left join 的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉。
假设有两张表: 表1:tab2 idsize110220330 表2:tab2 sizename10AAA20BBB20CCC 两条 SQL: select * form tab1 left join tab2 on (tab1.size = tab2.size) where tab2.name=’AAA’ select * form tab1 left join tab2 on (tab1.size = tab2.size and tab2.name=’AAA’)
第一条SQL的过程: 1、中间表 on条件: tab1.size = tab2.sizetab1.idtab1.sizetab2.sizetab2.name11010AAA22020BBB22020CCC330(null)(null) 2、再对中间表过滤 where 条件: tab2.name=’AAA’tab1.idtab1.sizetab2.sizetab2.name11010AAA 第二条SQL的过程: 1、中间表 on条件: tab1.size = tab2.size and tab2.name=’AAA’ (条件不为真也会返回左表中的录)
tab1.idtab1.sizetab2.sizetab2.name11010AAA220(null)(null)330(null)(null) 其实以上结果的关键原因就是 left join、right join、full join 的特殊性,不管 on 上的条件是否为真都会返回 left 或 right 表中的记录,full 则具有 left 和 right 的特性的并集。 而 inner jion没这个特殊性,则条件放在 on 中和 where 中,返回的结果集是相同的
###MySQL中通过EXPLAIN如何分析SQL的执行计划详解
1、type=ALL,全表扫描,MySQL遍历全表来找到匹配行
一般是没有where条件或者where条件没有使用索引的查询语句
EXPLAIN SELECT * FROM customer WHERE active=0;

2、type=index,索引全扫描,MySQL遍历整个索引来查询匹配行,并不会扫描表
一般是查询的字段都有索引的查询语句
EXPLAIN SELECT store_id FROM customer;

3、type=range,索引范围扫描,常用于<、<=、>、>=、between等操作
EXPLAIN SELECT* FROM customer WHEREcustomer_id>=10 ANDcustomer_id<=20;

注意这种情况下比较的字段是需要加索引的,如果没有索引,则MySQL会进行全表扫描,如下面这种情况,create_date字段没有加索引:
EXPLAIN SELECT * FROM customer WHERE create_date>=’2006-02-13’ ;

4、type=ref,使用非唯一索引或唯一索引的前缀扫描,返回匹配某个单独值的记录行
store_id字段存在普通索引(非唯一索引)
EXPLAIN SELECT* FROMcustomer WHEREstore_id=10;

ref类型还经常会出现在join操作中:
customer、payment表关联查询,关联字段customer.customer_id(主键),payment.customer_id(非唯一索引)。表关联查询时必定会有一张表进行全表扫描,此表一定是几张表中记录行数最少的表,然后再通过非唯一索引寻找其他关联表中的匹配行,以此达到表关联时扫描行数最少。
因为customer、payment两表中customer表的记录行数最少,所以customer表进行全表扫描,payment表通过非唯一索引寻找匹配行。
EXPLAIN SELECT * FROM customer customer INNER JOIN payment payment ON customer.customer_id = payment.customer_id;

6、type=const/system,单表中最多有一条匹配行,查询起来非常迅速,所以这个匹配行的其他列的值可以被优化器在当前查询中当作常量来处理
const/system出现在根据主键primary key或者 唯一索引 unique index 进行的查询
根据主键primary key进行的查询:
EXPLAIN SELECT* FROMcustomer WHEREcustomer_id =10;

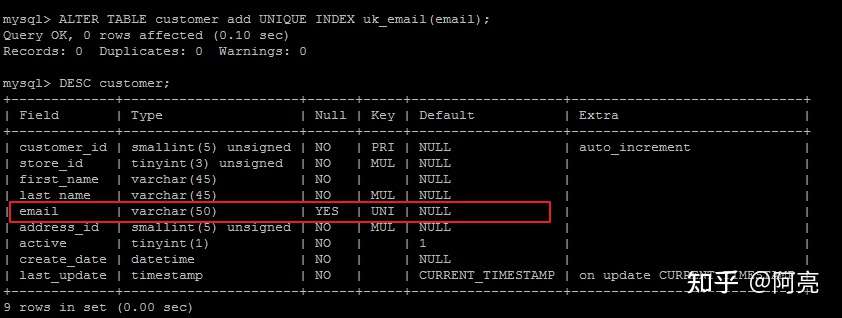
根据唯一索引unique index进行的查询:
EXPLAIN SELECT * FROM customer WHERE email ='MARY.SMITH@sakilacustomer.org';
7、type=NULL,MySQL不用访问表或者索引,直接就能够得到结果

.possible_keys: 表示查询可能使用的索引
.key: 实际使用的索引
.key_len: 使用索引字段的长度
.ref: 使用哪个列或常数与key一起从表中选择行。
.rows: 扫描行的数量
.filtered: 存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例(百分比)
.Extra: 执行情况的说明和描述,包含不适合在其他列中显示但是对执行计划非常重要的额外信息
最主要的有一下三种:
| Using Index | 表示索引覆盖,不会回表查询 |
|---|---|
| Using Where | 表示进行了回表查询 |
| Using Index Condition | 表示进行了ICP优化 |
| Using Flesort | 表示MySQL需额外排序操作, 不能通过索引顺序达到排序效果 |
使用B树的好处
B树可以在内部节点同时存储键和值,因此,把频繁访问的数据放在靠近根节点的地方将会大大提高热点数据的查询效率。这种特性使得B树在特定数据重复多次查询的场景中更加高效。
使用B+树的好处
由于B+树的内部节点只存放键,不存放值,因此,一次读取,可以在内存页中获取更多的键,有利于更快地缩小查找范围。 B+树的叶节点由一条链相连,因此,当需要进行一次全数据遍历的时候(在范围数据查找情况下),B+树只需要使用O(logN)时间找到最小的一个节点,然后通过链进行O(N)的顺序遍历即可。而B树则需要对树的每一层进行遍历,这会需要更多的内存置换次数(更多的磁盘IO),因此也就需要花费更多的时间
数据库为什么使用B+树而不是B树
- B树只适合随机检索,而B+树同时支持随机检索和顺序检索;
- B+树空间利用率更高,可减少I/O次数,磁盘读写代价更低。一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗。B+树的内部结点并没有指向关键字具体信息的指针,只是作为索引使用,其内部结点比B树小,盘块能容纳的结点中关键字数量更多,一次性读入内存中可以查找的关键字也就越多,相对的,IO读写次数也就降低了。而IO读写次数是影响索引检索效率的最大因素;
- B+树的查询效率更加稳定。B树搜索有可能会在非叶子结点结束,越靠近根节点的记录查找时间越短,只要找到关键字即可确定记录的存在,其性能等价于在关键字全集内做一次二分查找。而在B+树中,顺序检索比较明显,随机检索时,任何关键字的查找都必须走一条从根节点到叶节点的路,所有关键字的查找路径长度相同,导致每一个关键字的查询效率相当。
- B-树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。B+树的叶子节点使用指针顺序连接在一起,只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作。
- 增删文件(节点)时,效率更高。因为B+树的叶子节点包含所有关键字,并以有序的链表结构存储,这样可很好提高增删效率。
B+树在满足聚簇索引和覆盖索引的时候不需要回表查询数据,
在B+树的索引中,叶子节点可能存储了当前的key值,也可能存储了当前的key值以及整行的数据,这就是聚簇索引和非聚簇索引。 在InnoDB中,只有主键索引是聚簇索引,如果没有主键,则挑选一个唯一键建立聚簇索引。如果没有唯一键,则隐式的生成一个键来建立聚簇索引。
当查询使用聚簇索引时,在对应的叶子节点,可以获取到整行数据,因此不用再次进行回表查询
###开启MySQL慢查询日志
配置项:slow_query_log
可以使用show variables like ‘slow_query_log%’ 查看是否开启,如果状态值为OFF,可以使用set GLOBAL slow_query_log = on来开启,它会在datadir下产生一个xxx-slow.log的文件。
设置临界时间
配置项:long_query_time
查看:show VARIABLES like ‘long_query_time’;,单位秒
设置:set long_query_time=0.5
实操时应该从长时间设置到短的时间,即将最慢的SQL优化掉
查看日志,一旦SQL超过了我们设置的临界时间就会被记录到xxx-slow.log中
为什么要内存对齐
- 平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
- 性能原因:数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
- 假如没有内存对齐机制,数据可以任意存放,现在一个int变量存放在从地址1开始的联系四个字节地址中,该处理器去取数据时,要先从0地址开始读取第一个4字节块,剔除不想要的字节(0地址),然后从地址4开始读取下一个4字节块,同样剔除不要的数据(5,6,7地址),最后留下的两块数据合并放入寄存器。这需要做很多工作。
- 现在有了内存对齐的,int类型数据只能存放在按照对齐规则的内存中,比如说0地址开始的内存。那么现在该处理器在取数据时一次性就能将数据读出来了,而且不需要做额外的操作,提高了效率。
内存对齐规则
- 基本类型的对齐值就是其sizeof值;
- 数据成员对齐规则:结构(struct)(或联合(union))的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员的对齐按照#pragma pack指定的数值和这个数据成员自身长度中,比较小的那个进行;
- 结构(或联合)的整体对齐规则:在数据成员完成各自对齐之后,结构(或联合)本身也要进行对齐,对齐将按照#pragma pack指定的数值和结构(或联合)最大数据成员长度中,比较小的那个进行;
//2020.05.12 公众号:C语言与CPP编程
#include<stdio.h>
struct
{
int i;
char c1;
char c2;
}Test1;
struct{
char c1;
int i;
char c2;
}Test2;
struct{
char c1;
char c2;
int i;
}Test3;
int main()
{
printf("%d\n",sizeof(Test1)); // 输出8
printf("%d\n",sizeof(Test2)); // 输出12
printf("%d\n",sizeof(Test3)); // 输出8
return 0;
}
默认#pragma pack(4),且结构体中最长的数据类型为4个字节,所以有效对齐单位为4字节,下面根据上面所说的规则以第二个结构体来分析其内存布局:首先使用规则1,对成员变量进行对齐:
- sizeof(c1) = 1 <= 4(有效对齐位),按照1字节对齐,占用第0单元;
- sizeof(i) = 4 <= 4(有效对齐位),相对于结构体首地址的偏移要为4的倍数,占用第4,5,6,7单元;
- sizeof(c2) = 1 <= 4(有效对齐位),相对于结构体首地址的偏移要为1的倍数,占用第8单元;
然后使用规则2,对结构体整体进行对齐:
第二个结构体中变量i占用内存最大占4字节,而有效对齐单位也为4字节,两者较小值就是4字节。因此整体也是按照4字节对齐。由规则1得到s2占9个字节,此处再按照规则2进行整体的4字节对齐,所以整个结构体占用12个字节。
根据上面的分析,不难得出上面例子三个结构体的内存布局如下:

例子三个结构体的内存布局
https://cloud.tencent.com/developer/article/1727794
1分钟内的Linux性能分析法
你登录到具有性能问题的Linux服务器时,第一分钟要检查什么?
在Netflix,我们拥有庞大的Linux EC2云实例,以及大量的性能分析工具来监视和调查它们的性能。这些工具包括Atlas和Vector。Atlas用于全云监控,Vector用于按需实例分析。这些工具能帮助我们解决大部分问题,但有时候我们仍需登录实例并运行一些标准的Linux性能工具。
Atlas:根据github上面的文档老许简单说一下自己的认知。一个可以管理基于时间维度数据的后端,同时具有内存存储功能可以非常快速地收集和报告大量指标。
Vector:Vector是一个主机上的性能监视框架,它可以将各种指标展示在工程师的浏览器上面。
总结
在这篇文章中,Netflix性能工程团队将向您展示通过命令行进行性能分析是,前60秒应该使用那些Linux标准工具。在60秒内,你可以通过以下10个命令来全面了解系统资源使用情况和正在运行的进程。首先寻找错误和饱和指标,因为他们很容易理解,然后是资源利用率。饱和是指资源负载超出其处理能力,其可以表现为一个请求队列的长度或者等待时间。
uptime
dmesg | tail
vmstat 1
mpstat -P ALL 1
pidstat 1
iostat -xz 1
free -m
sar -n DEV 1
sar -n TCP,ETCP 1
top
其中一些命令需要安装sysstat软件包。这些命令暴露的指标是一种帮助你完成USE Method(Utilization Saturation and Errors Method)——一种查找性能瓶颈的方法。这涉及检查所有资源(CPU、内存、磁盘等)利用率,饱和度和错误等指标。同时还需注意通过排除法可以逐步缩小资源检查范围。
以下各节通过生产系统中的示例总结了这些命令。这些命令的更多信息,请参考使用手册。
uptime
$ uptime
23:51:26 up 21:31, 1 user, load average: 30.02, 26.43, 19.02
这是一种快速查看平均负载的方法,它指示了等待运行的进程数量。在Linux系统上,这些数字包括要在CPU上运行的进程以及处于I/O(通常是磁盘I/O)阻塞的进程。这提供了资源负载的大概状态,没有其他工具就无法理解更多。仅值得一看。
这三个数字分别代表着1分钟、5分钟和15分钟内的平均负载。这三个指标让我们了解负载是如何随时间变化的。例如,你被要求检查有问题的服务器,而1分钟的值远低于15分钟的值,则意味着你可能登录的太晚而错过了问题现场。
在上面的例子中,最近的平均负载增加,一分钟值达到30,而15分钟值达到19。数字如此之大意味着很多:可能是CPU需求(可以通过后文中介绍的vmstat或mpstat命令来确认)。
dmesg | tail
$ dmesg | tail
[1880957.563150] perl invoked oom-killer: gfp_mask=0x280da, order=0, oom_score_adj=0
[...]
[1880957.563400] Out of memory: Kill process 18694 (perl) score 246 or sacrifice child
[1880957.563408] Killed process 18694 (perl) total-vm:1972392kB, anon-rss:1953348kB, file-rss:0kB
[2320864.954447] TCP: Possible SYN flooding on port 7001. Dropping request. Check SNMP counters.
如果有消息,它将查看最近的10条系统消息。通过此命令查找可能导致性能问题的错误。上面的示例包括oom-killer和TCP丢弃请求。
不要错过这一步!dmesg始终值得被检查。
vmstat 1
$ vmstat 1
procs ---------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
34 0 0 200889792 73708 591828 0 0 0 5 6 10 96 1 3 0 0
32 0 0 200889920 73708 591860 0 0 0 592 13284 4282 98 1 1 0 0
32 0 0 200890112 73708 591860 0 0 0 0 9501 2154 99 1 0 0 0
32 0 0 200889568 73712 591856 0 0 0 48 11900 2459 99 0 0 0 0
32 0 0 200890208 73712 591860 0 0 0 0 15898 4840 98 1 1 0 0
^C
vmstat是虚拟内存状态的缩写。它在每一行上打印关键服务的统计信息。
vmstat在参数1下运行,以显示一秒钟的摘要。在某些版本中,第一行的某些列展示的是自启动以来的平均值,而不是前一秒的平均值。现在请跳过第一行,除非你想学习并记住那一列是那一列。
要检查的列:
- r:在CPU上运行并等待切换的进程数。这为确定CPU饱和比平均负载提供了更好的信号,因为它不包括I/O。简单来说就是:r的值大于CPU数量即为饱和状态。
- free:可用内存以字节为单位,如果数字很大,则说明你有足够的可用内存。
free -m命令能够更好的描述此状态。 - si, so:swap-ins和swap-outs. 如果这两个值不为0,则说明内存不足。
- us, sy, id, wa, st:这是总CPU时间的百分比。他们分别是用户时间、系统时间(内核)、空闲时间(包括I/O等待)、I/O等待和被盗时间(虚拟机所消耗的时间)。
最后关于us, sy, id, wa, st的解释和原文不太一样,所以老许贴一下vmstat手册中的解释。
通过用户时间+系统时间来确认CPU是否繁忙。如果有持续的等待I/O,意味着磁盘瓶颈。这是CPU空闲的时候,因为任务等待I/O被阻塞。你可以将I/O等待视为CPU空闲的另一种形式,同时它也提供了CPU为什么空闲的线索。
I/O处理需要消耗系统时间。一个系统时间占比较高(比如超过20%)值得进一步研究,可能是内核处理I/O的效率低下。
在上面的例子中,CPU时间几乎完全处于用户级别,即CPU时间几乎被应用程序占用。CPU平均利用率也超过90%,这不一定是问题,还需要通过r列的值检查饱和度。
mpstat -P ALL 1
$ mpstat -P ALL 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
07:38:49 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
07:38:50 PM all 98.47 0.00 0.75 0.00 0.00 0.00 0.00 0.00 0.00 0.78
07:38:50 PM 0 96.04 0.00 2.97 0.00 0.00 0.00 0.00 0.00 0.00 0.99
07:38:50 PM 1 97.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 2.00
07:38:50 PM 2 98.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 1.00
07:38:50 PM 3 96.97 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 3.03
[...]
此命令用于显示每个CPU的CPU时间明细,可用于检查不平衡的情况。单个热CPU可能是因为存在一个单线程应用。
pidstat 1
$ pidstat 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
07:41:02 PM UID PID %usr %system %guest %CPU CPU Command
07:41:03 PM 0 9 0.00 0.94 0.00 0.94 1 rcuos/0
07:41:03 PM 0 4214 5.66 5.66 0.00 11.32 15 mesos-slave
07:41:03 PM 0 4354 0.94 0.94 0.00 1.89 8 java
07:41:03 PM 0 6521 1596.23 1.89 0.00 1598.11 27 java
07:41:03 PM 0 6564 1571.70 7.55 0.00 1579.25 28 java
07:41:03 PM 60004 60154 0.94 4.72 0.00 5.66 9 pidstat
07:41:03 PM UID PID %usr %system %guest %CPU CPU Command
07:41:04 PM 0 4214 6.00 2.00 0.00 8.00 15 mesos-slave
07:41:04 PM 0 6521 1590.00 1.00 0.00 1591.00 27 java
07:41:04 PM 0 6564 1573.00 10.00 0.00 1583.00 28 java
07:41:04 PM 108 6718 1.00 0.00 0.00 1.00 0 snmp-pass
07:41:04 PM 60004 60154 1.00 4.00 0.00 5.00 9 pidstat
^C
pidstat有点像top的每个进程摘要,但是会打印滚动摘要,而不是清除屏幕。这对于观察随时间变化的模式很有用,还可以将看到的内容记录下来。
上面的示例中,两个java进程消耗了大部分CPU时间。%CPU这一列是所有CPU的总和。1591%意味着java进程几乎耗尽了16个CPU。
iostat -xz 1
$ iostat -xz 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
73.96 0.00 3.73 0.03 0.06 22.21
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
xvda 0.00 0.23 0.21 0.18 4.52 2.08 34.37 0.00 9.98 13.80 5.42 2.44 0.09
xvdb 0.01 0.00 1.02 8.94 127.97 598.53 145.79 0.00 0.43 1.78 0.28 0.25 0.25
xvdc 0.01 0.00 1.02 8.86 127.79 595.94 146.50 0.00 0.45 1.82 0.30 0.27 0.26
dm-0 0.00 0.00 0.69 2.32 10.47 31.69 28.01 0.01 3.23 0.71 3.98 0.13 0.04
dm-1 0.00 0.00 0.00 0.94 0.01 3.78 8.00 0.33 345.84 0.04 346.81 0.01 0.00
dm-2 0.00 0.00 0.09 0.07 1.35 0.36 22.50 0.00 2.55 0.23 5.62 1.78 0.03
[...]
^C
这是一个非常好的工具,不仅可以了解块设备(磁盘)的工作负载还可以了解其性能。
- r/s, w/s, rkB/s, wkB/s:分别表示每秒交付给设备的读写请求数和每秒读写的KB数。这些可以描述设备的工作负载。性能问题可能仅仅是由于施加了过多的负载。
- await:I/O处理时间(毫秒为单位),这包括队列中请求所花费的时间以及为请求服务所花费的时间。如果值大于预期的平均时间,可能是因为设备已经饱和或设备出现问题。
- avgqu-sz:发送给设备请求的平均队列长度。该值大于1表明设备已达饱和状态(尽管设备通常可以并行处理请求,尤其是有多个后端磁盘的虚拟设备)。
- %util:设备利用率。这是一个显示设备是否忙碌的百分比,其含义为设备每秒的工作时间占比。该值大于60%时通常会导致性能不佳(可以在await中看出来),不过它也和具体的设备有关。值接近100%时,意味着设备已饱和。
关于avgqu-sz的解释和原文不太一样,所以老许贴一下iostat手册中的解释。
如果存储设备是位于很多磁盘前面的逻辑磁盘设备,则100%利用率可能仅仅意味着所有时间都在处理I/O,但是后端磁盘可能远远还没有饱和,而且还能处理更多的工作。
请记住,磁盘I/O性能不佳不一定是应用程序的问题。通常使用许多技术来异步执行I/O,以保证应用程序不被阻塞或直接遭受延迟(例如,预读用于读取,缓冲用于写入)。
free -m
$ free -m
total used free shared buffers cached
Mem: 245998 24545 221453 83 59 541
-/+ buffers/cache: 23944 222053
Swap: 0 0 0
看最右边两列:
- buffers:缓冲区缓存,用于块设备I/O。
- cached:页缓存,用于文件系统。
我们检查他们的值是否接近0,接近0会导致更高的磁盘I/O(可以通过iostat来确认)以及更糟糕的磁盘性能。上面的示例看起来不错,每个值都有许多兆字节。
-/+ buffers/cache为已用内存和可用内存提供更加清晰的描述。Linux将部分空闲内存用作缓存,但是在应用程序需要时可以快速回收。因此,用作缓存的内存应该应该以某种方式包含在free这一列,-/+ buffers/cache这一行就是做这个事情的。
上面这一段翻译,可能比较抽象,感觉说的不像人话,老许来转述成人能理解的话:
total = used + free
used = (-/+ buffers/cache这一行used对应列) + buffers + cached
=> 24545 = 23944 + 59 + 541
free = (-/+ buffers/cache这一行free对应列) - buffers - cached
=> 221453 = 222053 - 59 - 541
如果在Linux使用了ZFS会令人更加疑惑(就像我们对某些服务所做的一样),因为ZFS有自己的文件系统缓存。而free -m并不能正确反应该文件系统缓存。它可能表现为,系统可用内存不足,而实际上该内存可根据需要从ZFS缓存中使用。
ZFS: Zettabyte File System,也叫动态文件系统,更多信息见百度百科
sar -n DEV 1
$ sar -n DEV 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
12:16:48 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
12:16:49 AM eth0 18763.00 5032.00 20686.42 478.30 0.00 0.00 0.00 0.00
12:16:49 AM lo 14.00 14.00 1.36 1.36 0.00 0.00 0.00 0.00
12:16:49 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
12:16:49 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
12:16:50 AM eth0 19763.00 5101.00 21999.10 482.56 0.00 0.00 0.00 0.00
12:16:50 AM lo 20.00 20.00 3.25 3.25 0.00 0.00 0.00 0.00
12:16:50 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
^C
可以用这个工具检查网络接口的吞吐量: rxkB/s和txkB/s。作为工作负载的度量,还可以检查吞吐量是否达到上限。在上面的列子中,eth0的接受速度达到22Mbyte/s(176Mbit/s),该值远低于1Gbit/s的限制。
原文中无rxkB/s和txkB/s的解释,老许特意找了使用手册中的说明。
这个版本还有%ifutil作设备利用率,这也是我们使用Brendan的nicstat工具来测量的。和nicstat工具一样,这很难正确,而且本例中看起来该值并不起作用。
老许试了一下自己的云服务发现%ifutil指标并不一定都有。
sar -n TCP,ETCP 1
$ sar -n TCP,ETCP 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
12:17:19 AM active/s passive/s iseg/s oseg/s
12:17:20 AM 1.00 0.00 10233.00 18846.00
12:17:19 AM atmptf/s estres/s retrans/s isegerr/s orsts/s
12:17:20 AM 0.00 0.00 0.00 0.00 0.00
12:17:20 AM active/s passive/s iseg/s oseg/s
12:17:21 AM 1.00 0.00 8359.00 6039.00
12:17:20 AM atmptf/s estres/s retrans/s isegerr/s orsts/s
12:17:21 AM 0.00 0.00 0.00 0.00 0.00
^C
这是一些关键TCP指标的总结。其中包括:
- active/s:本地每秒启动的TCP连接数(例如,通过connect())。
- passive/s:远程每秒启动的TCP连接数(例如,通过accept())
- retrans/s:TCP每秒重传次数。
active和passive连接数通常用于服务器负载的粗略度量。将active视为向外的连接,passive视为向内的连接可能会有帮助,但这样区分并不严格(例如,localhost连接到localhost)。
重传是网络或服务器出问题的迹象。它可能是不可靠的网络(例如,公共Internet),也可能是由于服务器过载并丢弃了数据包。上面的示例显示每秒仅一个新的TCP连接。
top
$ top
top - 00:15:40 up 21:56, 1 user, load average: 31.09, 29.87, 29.92
Tasks: 871 total, 1 running, 868 sleeping, 0 stopped, 2 zombie
%Cpu(s): 96.8 us, 0.4 sy, 0.0 ni, 2.7 id, 0.1 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem: 25190241+total, 24921688 used, 22698073+free, 60448 buffers
KiB Swap: 0 total, 0 used, 0 free. 554208 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
20248 root 20 0 0.227t 0.012t 18748 S 3090 5.2 29812:58 java
4213 root 20 0 2722544 64640 44232 S 23.5 0.0 233:35.37 mesos-slave
66128 titancl+ 20 0 24344 2332 1172 R 1.0 0.0 0:00.07 top
5235 root 20 0 38.227g 547004 49996 S 0.7 0.2 2:02.74 java
4299 root 20 0 20.015g 2.682g 16836 S 0.3 1.1 33:14.42 java
1 root 20 0 33620 2920 1496 S 0.0 0.0 0:03.82 init
2 root 20 0 0 0 0 S 0.0 0.0 0:00.02 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:05.35 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
6 root 20 0 0 0 0 S 0.0 0.0 0:06.94 kworker/u256:0
8 root 20 0 0 0 0 S 0.0 0.0 2:38.05 rcu_sched
top命令包含我们之前检查的许多指标。运行它可以很方便地查看是否有任何东西和之前的命令结果差别很大。
top的缺点是随着时间推移不能看到相关变化,像vmstat和pidstat之类提供滚动输出的工具则能体现的更加清楚。如果你没有足够快地暂停输出(Ctrl-S暂停, Ctrl-Q继续上海居住证转户口),随着屏幕的清除间歇性问题的证据很有可能丢失。
###Golang map作为函数参数时在函数参数内部对 map 的操作会影响 map 自身
makemap 和 makeslice 的区别,带来一个不同点:当 map 和 slice 作为函数参数时,在函数参数内部对 map 的操作会影响 map 自身;而对 slice 却不会(之前讲 slice 的文章里有讲过)。
主要原因:一个是指针(*hmap),一个是结构体(slice)。Go 语言中的函数传参都是值传递,在函数内部,参数会被 copy 到本地。*hmap指针 copy 完之后,仍然指向同一个 map,因此函数内部对 map 的操作会影响实参(指针是copy的,但是指针所指的地址仍然是同一个)。而 slice 被 copy 后,会成为一个新的 slice,对它进行的操作不会影响到实参
###乘除取余转为位运算
取模运算转化成位运算 (在不产生溢出的情况下) a % (2^n) 等价于 a & (2^n - 1) 乘法运算转化成位运算 (在不产生溢出的情况下) a * (2^n) 等价于 a« n 除法运算转化成位运算 (在不产生溢出的情况下) a / (2^n) 等价于 a» n 例: 12/8 == 12»3 a % 2 等价于 a & 1
gRPC在K8s中的负载均衡问题
However, gRPC also breaks the standard connection-level load balancing, including what’s provided by Kubernetes. This is because gRPC is built on HTTP/2, and HTTP/2 is designed to have a single long-lived TCP connection, across which all requests are multiplexed—meaning multiple requests can be active on the same connection at any point in time. Normally, this is great, as it reduces the overhead of connection management. However, it also means that (as you might imagine) connection-level balancing isn’t very useful. Once the connection is established, there’s no more balancing to be done. All requests will get pinned to a single destination pod …
解决方案:
- Linkerd
- Nginx
- Istio
选择使用了内部的Istio方案
gRPC Load Balancing on Kubernetes without Tears
https://pandaychen.github.io/2020/06/01/K8S-LOADBALANCE-WITH-KUBERESOLVER/
分布式定时任务实现方式
- 分布式锁处理分布式一致性
- 使用Redis的有序集合(Sorted Set)将要执行任务的ID和毫秒时间戳ZAdd到有序集合中
- 定时1秒去执行消费定任务任务方法
- 消费方法加分布式锁,避免重复消息,通过死循环获取有序集合最小的时间戳与当前时间戳做对比,如果小于则执行,如果大于等线程等待100ms后继续下一次循环
elastic-job、Quartz一类分布式调度架构也可以实现
MQ消息队列
简单的算法数据结构设计是:小顶堆、时间轮算法
递归与回溯的区别
回溯是递归的一个子集, 回溯在递归的代码逻辑中还有for循环的部分
// 全排列的例子
var res [][]int
func permute(nums []int) [][]int {
res = make([][]int, 0)
used := make(map[int]struct{})
dfs(nums, []int{}, 0, used)
return res
}
func dfs(nums, tmp []int, start int, used map[int]struct{}) {
if len(tmp) == len(nums) {
cp := make([]int, len(tmp))
copy(cp, tmp)
res = append(res, cp)
return
}
// 回溯需要used 来过滤重复数字的情况,如果数字可以重复使用则不需要used
for i := 0; i < len(nums); i++ {
if _, ok := used[nums[i]]; ok {
continue
}
tmp = append(tmp, nums[i])
used[nums[i]] = struct{}{}
dfs(nums, tmp, i+1, used)
tmp = tmp[:len(tmp)-1]
delete(used, nums[i])
}
}
无法对 map 的 key 或 value 进行取地址
package main
import "fmt"
func main() {
m := make(map[string]int)
fmt.Println(&m["qcrao"])
}
如果通过其他 hack 的方式,例如 unsafe.Pointer 等获取到了 key 或 value 的地址,也不能长期持有,因为一旦发生扩容,key 和 value 的位置就会改变,之前保存的地址也就失效了。
###Go GC选择三色标记法
Go 的编译器会通过逃逸分析将大部分新生对象存储在栈上(栈直接被回收),只有那些需要长期存在的对象才会被分配到需要进行垃圾回收的堆中。也就是说,分代 GC 回收的那些存活时间短的对象在 Go 中是直接被分配到栈上,当 goroutine 死亡后栈也会被直接回收,不需要 GC 的参与,进而分代假设并没有带来直接优势。并且 Go 的垃圾回收器与用户代码并发执行,使得 STW 的时间与对象的代际、对象的 size 没有关系。Go 团队更关注于如何更好地让 GC 与用户代码并发执行(使用适当的 CPU 来执行垃圾回收),而非减少停顿时间这一单一目标上
尽管 STW 如今已经优化到了半毫秒级别以下,但这个程序被卡死原因是由于需要进入 STW 导致的。原因在于,GC 在需要进入 STW 时,需要通知并让所有的用户态代码停止,但是 for {} 所在的 goroutine 永远都不会被中断,从而始终无法进入 STW 阶段。实际实践中也是如此,当程序的某个 goroutine 长时间得不到停止,强行拖慢进入 STW 的时机,这种情况下造成的影响(卡死)是非常可怕的。好在自 Go 1.14 之后,这类 goroutine 能够被异步地抢占,从而使得进入 STW 的时间不会超过抢占信号触发的周期,程序也不会因为仅仅等待一个 goroutine 的停止而停顿在进入 STW 之前的操作上
根节点root数据指的是全局变量和函数栈
https://golang.design/go-questions/memgc/principal/
https://studygolang.com/articles/27243
https://www.jianshu.com/p/bfc3c65c05d1?utm_source=wechat_session
通过普罗米修斯监控发现Go GC耗时
1.14.2版本,max GC都在1ms以下。平均GC是200-500us。只针对本服务,没有普遍性。只是对GC的时间有个概念
时间轮算法了解
https://yfscfs.gitee.io/post/%E4%BB%A4%E4%BA%BA%E6%83%8A%E8%89%B3%E7%9A%84%E6%97%B6%E9%97%B4%E8%BD%AE%E7%AE%97%E6%B3%95timingwheel/
http://www.cs.columbia.edu/~nahum/w6998/papers/ton97-timing-wheels.pdf
https://blog.csdn.net/xinzhongtianxia/article/details/86221241
Docker 版本太低导致容器内访问IPv6地址失败
docker的老版本容器内访问IPv6地址有问题,无法成功。这个bug已经在新版本修复
TiDB的ORDER BY 与MySQL的不同
比如 MySQL ORDER BY created_at 操作,每次得到的结果顺序都是一致的,而TiDB当记录的created_at 值相同的时候,得到的结果顺序会有几率不同,原本A记录在B记录的前面,下一次查询,A记录在B记录后面。这样会导致分页的时候出现问题。在点击当前页的时候,A记录在最后一个记录,点击第二页的时候,A记录又出现在了第一个记录位置。
个人理解是MySQL在最后返回数据时,还会根据主键来排序,再返回,而TiDB没有。
TiDB要完全避免这种情况可以这样:ORDER BY created_at,id 加上主键一起ORDER BY
相比堆为什么栈上分配对象速度更快
- 每个线程都有一个独立的栈,一般是8M,这样分配在这个栈上底层的库不用加锁。
- 分配的速度也更快,空间已经分配好了,移动寻址就行。而堆不行
缺点:
- 栈大小有限,超过大小就栈溢出了(比如:递归)
- 生命周期有限,函数退出,返回了就释放了