automaxprocs解决容器获取真实配置的CPU核心数量,解决golang调度G-M平衡
K8s使用时,pod的服务通常都对 CPU 资源做了限制,例如默认的 4C。但是在容器里通过 lscpu 仍然能看到宿主机的所有 CPU 核心。这就导致 golang 服务默认会拿宿主机的 CPU 核心数来调用 runtime.GOMAXPROCS(),导致 P 数量远远大于可用的 CPU 核心(M),在高并发,产生大量goroutine时,引起频繁上下文切换,影响高负载情况下的服务性能。
runtime.GOMAXPROCS() 获取的是 宿主机的 CPU 逻辑核数 。P 值设置过大,导致生成线程M过多,会增加上下文切换的负担,导致严重的上下文切换,浪费 CPU
automaxprocs
package main
import (
"fmt"
_ "go.uber.org/automaxprocs"
"runtime"
)
func main() {
// Your application logic here.
fmt.Println("real GOMAXPROCS", runtime.GOMAXPROCS(-1))
}
https://kingsamchen.github.io/2019/11/09/src-study-uber-automaxprocs/
https://kingsamchen.github.io/2019/11/09/src-study-uber-automaxprocs/
TiDB对join 连表加order by的查询方式优化不好,经常导致索引失效而产生慢查询
KMP算法的nextArr数组
nextArr[i]的含义是在match[i]之前的字符串match[0..i-1]中,必须以match[i-1]结尾的后缀子串(不能包含match[0])与以match[0]开头的前缀子串(不包含match[i-1])最大匹配长度是多少。这个长度就是nextArr的值
短网址的一种方式
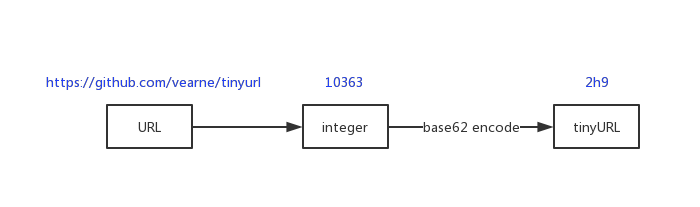
1) 将长地址与一个整数建立映射(一对多)
这里整数使用int64,保存映射关系。笔者为了简单使用是MySQL数据库,如果为了更好的并发存储,还可以NoSQL数据库或者数据分分库分表。
"https://github.com/vearne/tinyurl" -> 10363
这里主键id就是整数值 长地址存储在url字段中
+-------+---------------------------------+---------------------+
| id | url | created_at |
+-------+---------------------------------+---------------------+
| 10000 | http://vearne.cc/archives/39217 | 2019-11-28 14:02:56 |
+-------+---------------------------------+---------------------+
提示 这里不能用哈希的原因是,哈希后的值如果太短则容易出现碰撞,如果太长则压缩的效率太低
修改完hosts文件之后,浏览器需要重启才能在浏览器生效
数据库(Mysql)连接无效(invalid connection)解决方案
一般连接数据库的代码库都有实现连接池,如golang语言database/sql库,其中SetConnMaxLifetime(d time.Duration)是用来设置连接池里每条连接关闭的时间,当d <= 0时,连接池里的连接永久重用,即永远都在连接池里,拿来就用,不管此连接是否真的有效(这里有问题,下面讲)。当d > 0时,到了时间d才会关闭连接,把连接移出连接池,但这并不是时间一到就关闭,因为当连接还在使用时会等连接完成之后,等下一个清理连接周期(周期为d)时会关闭连接,移出连接池。
Mysql为了防止空闲连接过多,超过了参数mysql_connection之后会拒绝新连接,mysql会自动关闭空闭连接超过wait_timeout参数的时间,会关闭使用中超过interactive_timeout参数的连接。
由于mysql会自动关闭超时连接,所以database/sql的SetConnMaxLifetime()不能设置为永久有效,要不然连接已经被mysql关闭了,但还是拿着失效的连接使用就会报invalid connection。
解决的方案就是SetConnMaxLifetime()设置的时间小于wait_timeout就行,一般建议wait_timeout/2
INSERT IGNORE、INSERT…ON DUPLICATE KEY UPDATE、REPLACE
- Inserting a duplicate key in columns with
PRIMARY KEYorUNIQUEconstraints. - Inserting a NULL into a column with a
NOT NULLconstraint. - Inserting a row to a partitioned table, but the values you insert don’t map to a partition.
INSERT IGNORE:then the row won’t actually be inserted if it results in a duplicate key. But the statement won’t generate an error. It generates a warning instead. 不会报error报错,而是一个warning
INSERT...ON DUPLICATE KEY UPDATE: 会更新对应的字段
REPLACE: 实际的操作是 DELETE 之后再INSERT。这样会引起一些情况:
- A new auto-increment ID is allocated.
- Dependent rows with foreign keys may be deleted (if you use cascading foreign keys) or else prevent the
REPLACE. - Triggers that fire on
DELETEare executed unnecessarily. - Side effects are propagated to replicas too
https://stackoverflow.com/questions/548541/insert-ignore-vs-insert-on-duplicate-key-update
Java HashMap的死循环问题
HashMap在并发的情况,发生扩容时,可能会产生循环链表,在执行get的时候,会触发死循环,引起CPU的100%问题,所以一定要避免在并发环境下使用HashMap。
生产环境无特殊情况建议使用ConcurrentHashmap
PS: 如果hashmap底层不是用链表的方式存储冲突value,而是开发地址生成法 用的是数组而不是链表存储,则不会出现死循环的问题
在Golang中,同样的使用Golang的map的时候必须要使用锁,sync.Map可以不用,不过sync.Map更加适合读多写少的场景,Concurrentmap也是不错的选择
http://alishangtian.com/2020/09/25/hashmap-deadcricle/
10大高性能开发tip
- I/O优化:零拷贝技术
- I/O优化:多路复用技术
- 线程池技术
- 无锁编程技术
- 进程间通信技术
- RPC && 序列化技术
- 数据库索引技术
- 缓存技术 && 布隆过滤器
- 全文搜索技术
- 负载均衡技术
http://alishangtian.com/2020/09/22/demond/
了解POSIX (Portable Operating System Interface 可移植操作系统接口)
一般情况下,应用程序通过应用编程接口(API)而不是直接通过系统调用来编程。这点很重要,因为应用程序使用的这种编程接口实际上并不需要和内核 提供的系统调用对应。一个API定义了一组应用程序使用的编程接口。它们可以实现成一个系统调用,也可以通过调用多个系统调用来实现,而完全不使用任何系 统调用也不存在问题。实际上,API可以在各种不同的操作系统上实现,给应用程序提供完全相同的接口,而它们本身在这些系统上的实现却可能迥异。
在Unix世界中,最流行的应用编程接口是基于POSIX标准的。从纯技术的角度看,POSIX是由IEEE的一组标准组成,其目标是提供一套大体上基于Unix的可移植操作系统标准。Linux是与POSIX兼容的。
POSIX是说明API和系统调用之间关系的一个极好例子。在大多数Unix系统上,根据POSIX而定义的API函数和系统调用之间有着直接关 系。实际上,POSIX标准就是仿照早期Unix系统的界面建立的。另一方面,许多操作系统,像Windows NT,尽管和Unix没有什么关系,也提供了与POSIX兼容的库。
Linux的系统调用像大多数Unix系统一样,作为C库的一部分提供如图5-1所示。如图5-1所示C库实现了Unix系统的主要API,包括标 准C库函数和系统调用。所有的C程序都可以使用C库,而由于C语言本身的特点,其他语言也可以很方便地把它们封装起来使用。此外,C库提供了POSIX的 绝大部分API。
从程序员的角度看,系统调用无关紧要;他们只需要跟API打交道就可以了。相反,内核只跟系统调用打交道;库函数及应用程序是怎么使用系统调用不是内核所关心的
系统线程切换和用户态纤程的切换消耗
- 系统线程上下文切换消耗: 1.2 us-2us
- 用户态纤程(Fiber、gorotiune、coroutinue)上下文切换消耗: 150-200ns
可以看到,系统线程的上下文切换消耗大概是用户态纤程的10倍
理解InnoDB索引(B+树)失效
索引数据在B+树中是按照排序构造的,这样才能使用二分查找快速的定位索引位置。
一个复合索引(a,b),在B+树中,是先按照a字段的数据排序,当a字段数据相等,再按b字段排序。
如果字段是字符串,则按照字符串的字母的排序方式。
如果WHERE查询不满足最左前缀匹配法则,则会出现下面的情况:
- 利用到了a字段索引,但没法利用到b字段索引
- 没有通过先查a字段开始,则整个索引都无法使用到
- LIKE的后缀和包含方式无法使用索引,因为无法使用字符串的排序规则,从而查找索引是无序的
实际上就是无法按照索引的排序规律,使用索引的排序进行快速的二分查找,从而变成可能需要全表扫描等方式获取数据。
MySQL的行锁、表锁、间隙锁对SQL的性能影响
InnoDB一般加的都是行锁,行锁粒度小,并发性能最高。但如果SQL没有使用到任何索引和主键或者导致了索引失效,就会触发为表锁。比如:
UPDATE user SET name = "test" WHERE name = 'foo' OR name = 'bar'
上面即使name有索引,因为OR导致索引失效,从而导致UPDATE操作加的是表锁
不如修改为:
UPDATE user SET name = "test" WHERE name = 'foo'
UPDATE user SET name = "test" WHERE name = 'bar'
间隙锁一般发生在WHERE一个范围中 ,比如:
UPDATE user SET age = 20 WHERE age > 0 AND age < 100
INSERT user VALUES(30)
第一个UPDATE语句在 age > 0 AND age < 100的数据之间加上了间隙锁
第二个INSERT age 30 的语句是会一直阻塞的,30在0-100之间,直到第一个语句的间隙锁释放了
总结:间隙锁和表锁对性能的影响都是很大的,所以WHERE 语句要避免表锁发生,尽量避免间隙锁的发生。让WHERE使用到索引,并且减少范围情况下的更新修改等
一个有用的语句:
SHOW status LIKE 'innodb_row_lock%'
可以得到数据库锁使用的情况
Innodb_row_lock_current_waits
Innodb_row_lock_time
Innodb_row_lock_time_avg
Innodb_row_lock_time_max
Innodb_row_lock_waits
如果这几个数据的值都很大,说明数据库当前锁的性能影响比较大。如果数据库性能很低,可以从这几个地方考虑一下
提高golang写日志的性能
golang 需要频繁写日志的时候,使用更高性能的json库,要么使用text format ,要么json format 的时候,特别主要下序列化的对象,使用struct, 序列化map的性能比较低