理解redis的单线与多线程程操作
IO多路复用程序接收到用户的请求后,全部推送到一个队列里,交给文件分派器。对于后续的操作,基于 Reactor 单线程模式实现, 整个过程都在一个线程里完成,因此 Redis 被称为是单线程的操作
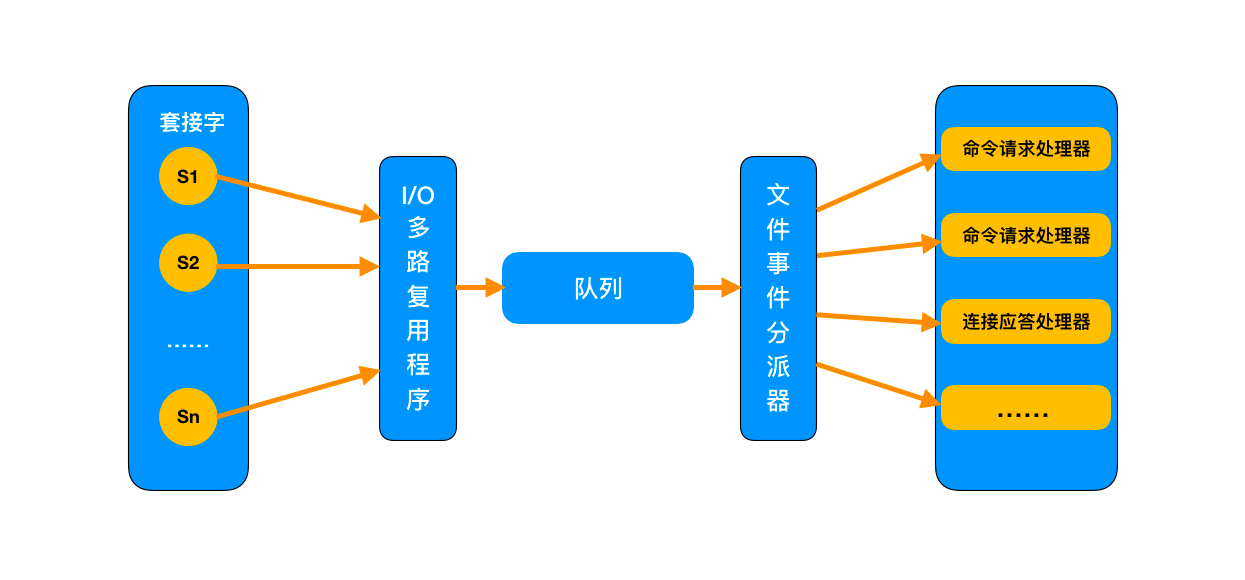
Redis基于Reactor模式开发了网络事件处理器,这个处理器被称为文件事件处理器。它的组成结构为4部分:多个套接字、IO多路复用程序、文件事件分派器、事件处理器。因为文件事件分派器队列的消费是单线程的,所以Redis才叫单线程模型。尽管多个文件事件可能会并发地出现,但I/O多路复用程序总是会将所有产生事件的套接字都推到一个队列里面,然后通过这个队列,以有序(sequentially)、同步(synchronously)、每次一个套接字的方式向文件事件分派器传送套接字:当上一个套接字产生的事件被处理完毕之后(该套接字为事件所关联的事件处理器执行完毕), I/O多路复用程序才会继续向文件事件分派器传送下一个套接字。
虽然整个文件事件处理器是在单线程上运行的,但是通过 I/O 多路复用模块的引入,实现了同时对多个 FD(文件描述符) 读写的监控,提高了网络通信模型的性能,同时也可以保证整个 Redis 服务实现的简单
Redis 是跑在单线程中的,所有的操作都是按照顺序线性执行的,但是由于读写操作等待用户输入或输出都是阻塞的,所以 I/O 操作在一般情况下往往不能直接返回,这会导致某一文件的 I/O 阻塞导致整个进程无法对其它客户提供服务,而 I/O 多路复用可以解决这个问题。但是对于大键值对这种情况,本身命令执行需要消耗大量时间,这样会阻塞redis主线程的执行,导致redis性能的下降,这种情况应该尽量避免
https://hogwartsrico.github.io/2020/06/24/Redis-and-Multiplexing/
首先第一个就是我前面提到过的,Redis 的多线程网络模型实际上并不是一个标准的 Multi-Reactors/Master-Workers 模型,和其他主流的开源网络服务器的模式有所区别,最大的不同就是在标准的 Multi-Reactors/Master-Workers 模式下,Sub Reactors/Workers 会完成
网络读 -> 数据解析 -> 命令执行 -> 网络写整套流程,Main Reactor/Master 只负责分派任务,而在 Redis 的多线程方案中,I/O 线程任务仅仅是通过 socket 读取客户端请求命令并解析,却没有真正去执行命令,所有客户端命令最后还需要回到主线程去执行,因此对多核的利用率并不算高,而且每次主线程都必须在分配完任务之后忙轮询等待所有 I/O 线程完成任务之后才能继续执行其他逻辑。Redis 之所以如此设计它的多线程网络模型,我认为主要的原因是为了保持兼容性,因为以前 Redis 是单线程的,所有的客户端命令都是在单线程的事件循环里执行的,也因此 Redis 里所有的数据结构都是非线程安全的,现在引入多线程,如果按照标准的 Multi-Reactors/Master-Workers 模式来实现,则所有内置的数据结构都必须重构成线程安全的,这个工作量无疑是巨大且麻烦的。
所以,在我看来,Redis 目前的多线程方案更像是一个折中的选择:既保持了原系统的兼容性,又能利用多核提升 I/O 性能。
其次,目前 Redis 的多线程模型中,主线程和 I/O 线程的通信过于简单粗暴:忙轮询和锁,因为通过自旋忙轮询进行等待,导致 Redis 在启动的时候以及运行期间偶尔会有短暂的 CPU 空转引起的高占用率,而且这个通信机制的最终实现看起来非常不直观和不简洁,希望后面 Redis 能对目前的方案加以改进。
Rabbitmq 一个消息并行事务如何实现
exchange有多个种类,常用的有direct,fanout,topic。前三种类似集合对应关系那样,(direct)1:1,(fanout)1:N,(topic)N:1。direct: 1:1类似完全匹配
fanout:1:N 可以把一个消息并行发布到多个队列上去,简单的说就是,当多个队列绑定到fanout的交换器,那么交换器一次性拷贝多个消息分别发送到绑定的队列上,每个队列有这个消息的副本。
ps:这个可以在业务上实现并行处理多个任务,比如,用户上传图片功能,当消息到达交换器上,它可以同时路由到积分 增加队列和其它队列上,达到并行处理的目的,并且易扩展,以后有什么并行任务的时候,直接绑定到fanout交换器 不需求改动之前的代码。 复制代码topic N:1 ,多个交换器可以路由消息到同一个队列。根据模糊匹配,比如一个队列的routing key 为*.test ,那么凡是到达交换器的消息中的routing key 后缀.test都被路由到这个队列上
当队列拥有多个消费者时,队列收到的消息将以轮询(负载均衡)的方式发送给消费者。每条消息只会发送给一个订阅的消费者
所以,如果想要将对消息进行并行处理事务 ,需要选择exchange fanout的模式,并且使用多个队列。没有办法通过一个队列多个消费者实现
Linux系统为什么分系统空间和用户空间
- 操作系统的数据都是存放于系统空间的,用户进程的数据是存放于用户空间的;
- 分开来存放,就让系统的数据和用户的数据互不干扰,保证系统的稳定性,并且管理上很方便;
- 也是重要的一点,将用户的数据和系统的数据隔离开,就可以对两部分的数据的访问进行控制。这样就可以确保用户程序不能随便操作系统的数据,这样防止用户程序误操作或者是恶意破坏系统
一篇关于ETCD 数据不一致排查牛逼的文章
https://stor.51cto.com/art/202004/615374.htm
Redis做分布式锁的问题
-
B的锁被A给释放了:每个线程加锁时要带上自己独有的value值来标识
-
数据库事务超时:一旦你的key长时间获取不到锁,获取锁等待的时间远超过数据库事务超时时间,数据库事务超时了,但是锁还没超时,程序就会报异常。(Java中会遇到,将事务改成手动提交和回滚)
-
锁过期了,业务还没执行完:类似redisson在加锁成功后,会注册一个定时任务监听这个锁,每隔10秒就去查看这个锁,如果还持有锁,就对过期时间进行续期。默认过期时间30秒。对正在持有的锁进行续期操作
-
Redis主从复制:redis cluster集群环境下,假如现在A客户端想要加锁,它会根据路由规则选择一台master节点写入key mylock,在加锁成功后,master节点会把key异步复制给对应的slave节点。
如果此时redis master节点宕机,为保证集群可用性,会进行主备切换,slave变为了redis master。B客户端在新的master节点上加锁成功,而A客户端也以为自己还是成功加了锁的。
此时就会导致同一时间内多个客户端对一个分布式锁完成了加锁,导致各种脏数据的产生。
如果只是一个redis cluster的方式做分布式锁,这种问题无法避免,所以有了RedLock的分布式锁方案,多节点redis实现的分布式锁算法(RedLock):有效防止单点故障。但是会引入RedLock自身的一些问题,需要具体权衡
三种更新缓存策略的优缺点
-
Cache Aside Pattern
读: 从缓存读取,缓存没有数据从数据库读取,之后更新缓存
写:先更新数据库,后删除缓存。这也是一种懒加载方式,只有缓存被需要的时候才会去计算。这样可以避免大量计算及频繁更新。如果是更新数据库更新缓存,会产生很大弊端,频繁更新浪费资源,如果这个缓存的数据计算成本比较高。比如为了一个数据,要通过多张表来计算才能得到结果。那么每修改一次,为了更新缓存还要再查询多张表来算一次
一个是查询操作,一个是更新操作的并发,首先,没有了删除cache数据的操作了,而是先更新了数据库中的数据,此时,缓存依然有效,所以,并发的查询操作拿的是没有更新的数据,但是,更新操作马上让缓存的失效了,后续的查询操作再把数据从数据库中拉出来。而不会像文章开头的那个逻辑产生的问题,后续的查询操作一直都在取老的数据
存在的问题:更新数据库成功,但删除缓存失败了。这就导致数据库中的数据是最新的,但缓存中却依然存着旧数据。而导致数据不一致,新的请求从缓存中读到的旧的数据。
另一个是:一个是读操作,但是没有命中缓存,然后就到数据库中取数据,此时来了一个写操作,写完数据库后,让缓存失效,然后,之前的那个读操作再把老的数据放进去,所以,会造成脏数据。
但,这个case理论上会出现,不过,实际上出现的概率可能非常低,因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要加锁,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大
最好还是为缓存设置上过期时间(或将两个操作放到一个事务中)
-
双写一致方案策略
先删除缓存再更新数据库:缓存删除成功,但更新数据库失败了,数据库还是旧的数据。新请求过来的话,缓存中没有数据,于是就到数据库读取了旧数据更新到缓存中。这其实是自洽的,数据库没更新成功,还是旧的数据,缓存被修改为旧的数据。
存在的问题:如果同时来了两个请求,一个写请求,一个读请求。
写请求先删除Redis中的数据,然后去数据库进行更新操作。
读请求判断Redis中有没有数据,没有数据时去请求数据库,拿到数据后写入缓存中。
但是写请求此时并没有更新成功,或者执行了一个事务还没有成功。
这样的话,读请求拿到未修改的旧数据写入缓存。过了一会儿,写请求将数据库更新成功了,那么此时缓存与库中的数据就不一致了
-
缓存延时双删策略
写请求过来先把 Redis缓存删掉,等数据库更新成功后,异步等待一段时间再次把缓存删掉。
这种方案读取速度快,但是会出现短时间的脏数据
这种方案解决了高并发情况下,同时有读请求与写请求时导致的不一致问题。读取速度快,但是可能会出现短时间的脏数据
https://coolshell.cn/articles/17416.html
在容器中如何修改/etc/hosts文件并生效
大部分容器镜像中比如:busybox,没有/etc/nsswitch.conf 文件,所以总是优先使用DNS解析,忽略了 /etc/hosts 文件。如果只是修改了/etc/hosts 并不会生效,DNS解析的时候,还是会先进行DNS服务器的解析。
解决办法很简单,给镜像添加 /etc/nsswitch.conf 文件指定解析顺序即可
hosts: files dns
表示files的优先级在dns前面,就会先去找/etc/hosts的域名对应关系
Redlock简记
https://www.cnblogs.com/rgcLOVEyaya/p/RGC_LOVE_YAYA_1003days.html
加锁命令
SET key_name my_random_value NX PX 30000 # NX 表示if not exist 就设置并返回True,否则不设置并返回False PX 表示过期时间用毫秒级, 30000 表示这些毫秒时间后此key过期
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
解锁方式使用执行Lua脚本,因为这种方式可以原子化操作
一个反射的报错:panic: reflect: call of reflect.Value.NumField on int Value
遇到了一个关于反射的报错:
panic: reflect: call of reflect.Value.NumField on int Value
代码追踪到:
// mustBe panics if f's kind is not expected.
// Making this a method on flag instead of on Value
// (and embedding flag in Value) means that we can write
// the very clear v.mustBe(Bool) and have it compile into
// v.flag.mustBe(Bool), which will only bother to copy the
// single important word for the receiver.
func (f flag) mustBe(expected Kind) {
if f.kind() != expected {
panic(&ValueError{methodName(), f.kind()})
}
}
知道这是个要接收期待的kind才能成功运行的方法,于是就去看看传入这个方法的kind是什么
// NumField returns the number of fields in the struct v.
// It panics if v's Kind is not Struct.
func (v Value) NumField() int {
v.mustBe(Struct)
tt := (*structType)(unsafe.Pointer(v.typ))
return len(tt.fields)
}
v需要的是结构体struct,而我传入的是count &int 指针
修改,构造一个结构体
type MyCount struct {
Count int
}
mco := &MyCount{}
mco代入方法中,取到的值会赋值给mco.Count
小结: 需要的是一个struct指针,而不是int指针
shell脚本实现分析nginx日志,自动封单个访问量大于指定值的IP
1.在nginx的nginx.conf中http段或者server段中引入拒绝访问的IP列表
include /usr/local/nginx/conf/blockip/*/*/*.conf;
2.写shell脚本实现分析访问日志,将国外IP写入到拒绝访问的IP列表
#!/bin/bash
#当单个IP访问量大于这个值得时候,封IP
max=1000
#nginx访问日志文件路径
logDir=/usr/local/nginx/logs/*.log
basePath='/usr/local/nginx/conf/blockip/'
month=$(date -d yesterday +"%Y%m")
day=$(date -d yesterday +"%d")
mkdir -p $basePath/$month/$day
#nginx封锁配置文件路径
confDir=$basePath/$month/$day/${day}.conf
#截取IP段
cat $logDir|awk '{print $1}'|sort|uniq -c|sort -n|while read line
do
a=(`echo $line`)
#比较每个访问IP是否大于设定的max值
if [ $a -ge $max ]
then
#判断是否是IP地址格式,这里并非严格意义上的判断
echo ${a[1]}|egrep -q '([0-9]+\.){3}[0-9]+'
if [ $? -eq 0 ]; then
curlResult=`curl http://ip-api.com/json/${a[1]}`
chinaStr=China
successStr=success
if [[ $curlResult =~ $successStr && ! $curlResult =~ $chinaStr ]]
then
#把“deny IP;”语句写入封锁配置文件中
echo "deny ${a[1]};">>$confDir
fi
fi
fi
done
/usr/local/nginx/sbin/nginx -s reload
golang grace平滑重启的实际操作例子描述
// curl “http://127.0.0.1:5001/sleep?duration=60s” &
1.
lsof -i:5001
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
example 62844 pathbox 8u IPv6 0x4ce79a57ef2f44a3 0t0 TCP *:commplex-link (LISTEN)
启动服务后,看到服务的PID是62844
2. 执行请求,这个请求会持续60秒,这个请求连接的
curl "http://127.0.0.1:5001/sleep?duration=60s" &
netstat -anlt| grep 5001
tcp4 0 0 127.0.0.1.5001 127.0.0.1.61724 ESTABLISHED
lsof -i:5001
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
example 62844 pathbox 4u IPv6 0x4ce79a57f7870183 0t0 TCP localhost:commplex-link->localhost:61748 (ESTABLISHED) 可以看到这个是curl和服务建立的连接
example 62844 pathbox 8u IPv6 0x4ce79a57ef2f44a3 0t0 TCP *:commplex-link (LISTEN)
3.
kill -USR2 62844
再执行:
lsof -i:5001
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
example 62844 pathbox 4u IPv6 0x4ce79a57f7870183 0t0 TCP localhost:commplex-link->localhost:61748 (ESTABLISHED)
curl 65640 pathbox 3u IPv4 0x4ce79a5804a1230b 0t0 TCP localhost:61748->localhost:commplex-link (ESTABLISHED)
example 65870 pathbox 8u IPv6 0x4ce79a57ef2f44a3 0t0 TCP *:commplex-link (LISTEN)
example 65870 pathbox 4u IPv6 0x4ce79a57ef2f3183 0t0 TCP localhost:commplex-link->localhost:61779 (ESTABLISHED)
curl 67548 pathbox 3u IPv4 0x4ce79a57f93cb153 0t0 TCP localhost:61779->localhost:commplex-link (ESTABLISHED)
kill -USR2已经执行了,看到新的LISTEN已经创建,PID是65870,但是curl 的连接还在一直还在执行,并没有因为kill操作而断了。
这时候再执行一个新的curl请求,新的请求:localhost:61779 连接是和新的服务进程PID65870 建立了连接,请的请求请求到了重启后的服务进程上,不会请求到旧的服务进程上。旧的服务进程等原有的请求执行完了,就释放了
4. 最后留下最新的服务进程
lsof -i:5001
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
example 65870 pathbox 8u IPv6 0x4ce79a57ef2f44a3 0t0 TCP *:commplex-link (LISTEN)
#####总结: grace重启后,旧的服务进程和新的服务进程同时存在,旧的服务进程在其原有的连接请求执行完后释放,新的请求会请求到新的服务进程进行处理
-
监听信号
-
收到信号时fork子进程(使用相同的启动命令),将服务监听的socket文件描述符传递给子进程
-
子进程监听父进程的socket,这个时候父进程和子进程都可以接收请求
-
子进程启动成功之后,父进程停止接收新的连接,等待旧连接处理完成(或超时)
-
父进程退出,升级完成
其他:
grace Hello world Hello Harry 2096 3100 旧API不会断掉,会执行原来的逻辑,pid会变化
endless Hello world Hello Harry 22072 22365 旧API不会断掉,会执行原来的逻辑,pid会变化
overseer Hello world Hello Harry 28300 28300 旧API不会断掉,会执行原来的逻辑,主进程pid不会变化
overseer是与grace和endless有些不同,主要是两点:
overseer添加了Fetcher,当Fetcher返回有效的二进位流(io.Reader) 时,主进程会将它保存到临时位置并验证它,替换当前的二进制文件并启动。
Fetcher运行在一个goroutine中,预先会配置好检查的间隔时间。Fetcher支持File、GitHub、HTTP和S3的方式。详细可查看包package fetcher
overseer添加了一个主进程管理平滑重启。子进程处理连接,能够保持主进程pid不变
OAuth2.0 授权码方式
OAuth2.0四种授权中授权码方式是最为复杂,但也是安全系数最高的,比较常用的一种方式。这种方式适用于兼具前后端的Web项目,因为有些项目只有后端或只有前端,并不适用授权码模式。
下图我们以用WX登录掘金为例(实质是掘金通过授权码拿到token然后通过token调用微信接口,得到微信个人数据,将微信个人数据存储到掘金作为在掘金的个人信息),详细看一下授权码方式的整体流程。
用户选择WX登录掘金,掘金会向WX发起授权请求,接下来 WX询问用户是否同意授权(常见的弹窗授权、扫码授权),这里和密码模式不同的是,用户输入账号密码给掘金,掘金再用账号密码去wx那验证授权,账号密码就暴露给掘金了。response_type 为 code 要求返回授权码,scope 参数表示本次授权范围为只读权限,redirect_uri 重定向地址。
A 网站让用户跳转到 GitHub。
GitHub 要求用户登录,然后询问"A 网站要求获得 xx 权限,你是否同意?"
用户同意,GitHub 就会重定向回 A 网站,同时发回一个授权码。
A 网站使用授权码,向 GitHub 请求令牌。
GitHub 返回令牌.
A 网站使用令牌,向 GitHub 请求用户数据。
从Snowflake理解云计算
Snowflake对于云计算的理解非常深入,运用出神入化。让我们不禁反思什么才是云应用,什么才是SaaS。如果只是把一个应用部署到了云环境上,那不是真正的云应用。我们是否:
真正的利用了云的无限扩展的存储和计算能力。
真正的让客户零运维、高可用,从而省心。
真正的让客户省钱。(不是只省一点,而是由几十万变为了几千几百元那种)