哈希算法(Hash Algorithm)
哈希算法(Hash Algorithm)又称散列算法、散列函数、哈希函数,是一种从任何一种数据中创建小的数字“指纹”的方法。哈希算法将数据重新打乱混合,重新创建一个哈希值。 哈希算法主要用来保障数据真实性(即完整性),即发信人将原始消息和哈希值一起发送,收信人通过相同的哈希函数来校验原始数据是否真实。 哈希算法通常有以下几个特点: 2 的 128 次方为 340282366920938463463374607431768211456,也就是 10 的 39 次方级别 2 的 160 次方为 1.4615016373309029182036848327163e+48,也就是 10 的 48 次方级别 2 的 256 次方为 1.1579208923731619542357098500869 × 10 的 77 次方,也就是 10 的 77 次方 正像快速:原始数据可以快速计算出哈希值 逆向困难:通过哈希值基本不可能推导出原始数据 输入敏感:原始数据只要有一点变动,得到的哈希值差别很大 冲突避免:很难找到不同的原始数据得到相同的哈希值,宇宙中原子数大约在 10 的 60 次方到 80 次方之间,所以 2 的 256 次方有足够的空间容纳所有的可能,算法好的情况下冲突碰撞的概率很低
session、token、JWT
https://zhuanlan.zhihu.com/p/164696755
Token 和 Session 的区别 Session 是一种记录服务器和客户端会话状态的机制,使服务端有状态化,可以记录会话信息。而 Token 是令牌,访问资源接口(API)时所需要的资源凭证。Token 使服务端无状态化,不会存储会话信息。 Session 和 Token 并不矛盾,作为身份认证 Token 安全性比 Session 好,因为每一个请求都有签名还能防止监听以及重放攻击,而 Session 就必须依赖链路层来保障通讯安全了。如果你需要实现有状态的会话,仍然可以增加 Session 来在服务器端保存一些状态。 所谓 Session 认证只是简单的把 User 信息存储到 Session 里,因为 SessionID 的不可预测性,暂且认为是安全的。而 Token ,如果指的是 OAuth Token 或类似的机制的话,提供的是 认证 和 授权 ,认证是针对用户,授权是针对 App 。其目的是让某 App 有权利访问某用户的信息。这里的 Token 是唯一的。不可以转移到其它 App上,也不可以转到其它用户上。Session 只提供一种简单的认证,即只要有此 SessionID ,即认为有此 User 的全部权利。是需要严格保密的,这个数据应该只保存在站方,不应该共享给其它网站或者第三方 App。所以简单来说:如果你的用户数据可能需要和第三方共享,或者允许第三方调用 API 接口,用 Token 。如果永远只是自己的网站,自己的 App,用什么就无所谓了
Token 和 JWT 的区别 相同: 都是访问资源的令牌 都可以记录用户的信息 都是使服务端无状态化 都是只有验证成功后,客户端才能访问服务端上受保护的资源 区别: Token:服务端验证客户端发送过来的 Token 时,还需要查询数据库获取用户信息,然后验证 Token 是否有效。 JWT:将 Token 和 Payload 加密后存储于客户端,服务端只需要使用密钥解密进行校验(校验也是 JWT 自己实现的)即可,不需要查询或者减少查询数据库,因为 JWT 自包含了用户信息和加密的数据。 常见的前后端鉴权方式 Session-Cookie Token 验证(包括 JWT,SSO) OAuth2.0(开放授权)
常见问题 使用 cookie 时需要考虑的问题 因为存储在客户端,容易被客户端篡改,使用前需要验证合法性 不要存储敏感数据,比如用户密码,账户余额 使用 httpOnly 在一定程度上提高安全性 尽量减少 cookie 的体积,能存储的数据量不能超过 4kb 设置正确的 domain 和 path,减少数据传输 cookie 无法跨域 一个浏览器针对一个网站最多存 20 个Cookie,浏览器一般只允许存放 300 个Cookie 移动端对 cookie 的支持不是很好,而 session 需要基于 cookie 实现,所以移动端常用的是 token 使用 session 时需要考虑的问题 将 session 存储在服务器里面,当用户同时在线量比较多时,这些 session 会占据较多的内存,需要在服务端定期的去清理过期的 session 当网站采用集群部署的时候,会遇到多台 web 服务器之间如何做 session 共享的问题。因为 session 是由单个服务器创建的,但是处理用户请求的服务器不一定是那个创建 session 的服务器,那么该服务器就无法拿到之前已经放入到 session 中的登录凭证之类的信息了。 当多个应用要共享 session 时,除了以上问题,还会遇到跨域问题,因为不同的应用可能部署的主机不一样,需要在各个应用做好 cookie 跨域的处理。 sessionId 是存储在 cookie 中的,假如浏览器禁止 cookie 或不支持 cookie 怎么办? 一般会把 sessionId 跟在 url 参数后面即重写 url,所以 session 不一定非得需要靠 cookie 实现 移动端对 cookie 的支持不是很好,而 session 需要基于 cookie 实现,所以移动端常用的是 token 使用 token 时需要考虑的问题 如果你认为用数据库来存储 token 会导致查询时间太长,可以选择放在内存当中。比如 redis 很适合你对 token 查询的需求。 token 完全由应用管理,所以它可以避开同源策略 token 可以避免 CSRF 攻击(因为不需要 cookie 了) 移动端对 cookie 的支持不是很好,而 session 需要基于 cookie 实现,所以移动端常用的是 token 使用 JWT 时需要考虑的问题 因为 JWT 并不依赖 Cookie 的,所以你可以使用任何域名提供你的 API 服务而不需要担心跨域资源共享问题(CORS) JWT 默认是不加密,但也是可以加密的。生成原始 Token 以后,可以用密钥再加密一次。 JWT 不加密的情况下,不能将秘密数据写入 JWT。 JWT 不仅可以用于认证,也可以用于交换信息。有效使用 JWT,可以降低服务器查询数据库的次数。 JWT 最大的优势是服务器不再需要存储 Session,使得服务器认证鉴权业务可以方便扩展。但这也是 JWT 最大的缺点:由于服务器不需要存储 Session 状态,因此使用过程中无法废弃某个 Token 或者更改 Token 的权限。也就是说一旦 JWT 签发了,到期之前就会始终有效,除非服务器部署额外的逻辑。 JWT 本身包含了认证信息,一旦泄露,任何人都可以获得该令牌的所有权限。为了减少盗用,JWT的有效期应该设置得比较短。对于一些比较重要的权限,使用时应该再次对用户进行认证。 JWT 适合一次性的命令认证,颁发一个有效期极短的 JWT,即使暴露了危险也很小,由于每次操作都会生成新的 JWT,因此也没必要保存 JWT,真正实现无状态。 为了减少盗用,JWT 不应该使用 HTTP 协议明码传输,要使用 HTTPS 协议传输。 使用加密算法时需要考虑的问题 绝不要以明文存储密码 永远使用 哈希算法 来处理密码,绝不要使用 Base64 或其他编码方式来存储密码,这和以明文存储密码是一样的,使用哈希,而不要使用编码。编码以及加密,都是双向的过程,而密码是保密的,应该只被它的所有者知道, 这个过程必须是单向的。哈希正是用于做这个的,从来没有解哈希这种说法, 但是编码就存在解码,加密就存在解密。 绝不要使用弱哈希或已被破解的哈希算法,像 MD5 或 SHA1 ,只使用强密码哈希算法。 绝不要以明文形式显示或发送密码,即使是对密码的所有者也应该这样。如果你需要 “忘记密码” 的功能,可以随机生成一个新的 一次性的(这点很重要)密码,然后把这个密码发送给用户
浅拷贝和深拷贝
浅拷贝只复制指向某个对象的指针,而不复制对象本身,新旧对象还是共享同一块内存。但深拷贝会另外创造一个一模一样的对象,新对象跟原对象不共享内存,修改新对象不会改到原对象
yml文件读取大数字
一个配置val:01234567890123432423454353453453543 读取这个大数字时会按照整数处理而报错。和使用的包中反射有关
一种不同数据库的双写方案简记:中间件监听+消息队列
数据库:Database、Redis、Elasticsearch、HDFS 对Database进行写操作时,中间件监听写操作,然后将消息写入Kafka消息队列,Redis、Elasticsearch、HDFS三者监听Kafka消息队列,将数据写入。如果kafka对重试机制并不友好,可以换成使用RocketMQ
Etcd 实现分布式锁的业务流程
https://tangxusc.github.io/blog/2019/05/etcd-lock%E8%AF%A6%E8%A7%A3/ 假设对某个共享资源设置的锁名为:/lock/mylock 步骤 1: 准备
客户端连接 Etcd,以 /lock/mylock 为前缀创建全局唯一的 key,假设第一个客户端对应的 key=”/lock/mylock/UUID1”,第二个为 key=”/lock/mylock/UUID2”;客户端分别为自己的 key 创建租约 - Lease,租约的长度根据业务耗时确定,假设为 15s;
步骤 2: 创建定时任务作为租约的“心跳”
当一个客户端持有锁期间,其它客户端只能等待,为了避免等待期间租约失效,客户端需创建一个定时任务作为“心跳”进行续约。此外,如果持有锁期间客户端崩溃,心跳停止,key 将因租约到期而被删除,从而锁释放,避免死锁。
步骤 3: 客户端将自己全局唯一的 key 写入 Etcd
进行 put 操作,将步骤 1 中创建的 key 绑定租约写入 Etcd,根据 Etcd 的 Revision 机制,假设两个客户端 put 操作返回的 Revision 分别为 1、2,客户端需记录 Revision 用以接下来判断自己是否获得锁。
步骤 4: 客户端判断是否获得锁
客户端以前缀 /lock/mylock 读取 keyValue 列表(keyValue 中带有 key 对应的 Revision),判断自己 key 的 Revision 是否为当前列表中最小的,如果是则认为获得锁;否则监听列表中前一个 Revision 比自己小的 key 的删除事件,一旦监听到删除事件或者因租约失效而删除的事件,则自己获得锁。
步骤 5: 执行业务
获得锁后,操作共享资源,执行业务代码。
步骤 6: 释放锁
完成业务流程后,删除对应的key释放锁
SELECT FOR UPDATE会锁表吗
如果WHERE条件没有用到索引或主键,则在事务提交前是表锁,否则是行锁。如果WHERE条件比较复杂,MySQL的执行计划有可能选择了非索引的方式查询,会导致锁表
对于多个同时的异步操作,需要保证顺序性的情况
比如:1异步上传了图片,2之后需要拿到该图片进行处理,1的顺序要在2的前面
乐观锁的简单实现
1.给表增加version字段
2.查询出机器信息:
select resource_id,version from resource where status=0 limit 1;
3.将该机器分配给该 job:
update resource set status=<job_id> where resource_id =<刚查出的> and version=<刚查出 version+1>;
for update仅适用于InnoDB,且必须在事务块(BEGIN/COMMIT)中才能生效
for update仅适用于InnoDB,且必须在事务块(BEGIN/COMMIT)中才能生效。在进行事务操作时,通过“for update”语句,MySQL会对查询结果集中每行数据都添加排他锁,其他线程对该记录的更新与删除操作都会阻塞。排他锁包含行锁、表锁
Linux 后台运行命令
nohup ./cmd 2>&1 >> cmd_log.log &
Ctrl c
ps aux | grep cmd
TCP建立连接可以两次握手吗?为什么?
展开
不可以。有两个原因:
首先,可能会出现已失效的连接请求报文段又传到了服务器端。
client 发出的第一个连接请求报文段并没有丢失,而是在某个网络结点长时间的滞留了,以致延误到连接释放以后的某个时间才到达 server。本来这是一个早已失效的报文段。但 server 收到此失效的连接请求报文段后,就误认为是 client 再次发出的一个新的连接请求。于是就向 client 发出确认报文段,同意建立连接。假设不采用 “三次握手”,那么只要 server 发出确认,新的连接就建立了。由于现在 client 并没有发出建立连接的请求,因此不会理睬 server 的确认,也不会向 server 发送数据。但 server 却以为新的运输连接已经建立,并一直等待 client 发来数据。这样,server 的很多资源就白白浪费掉了。采用 “三次握手” 的办法可以防止上述现象发生。例如刚才那种情况,client 不会向 server 的确认发出确认。server 由于收不到确认,就知道 client 并没有要求建立连接。
其次,两次握手无法保证Client正确接收第二次握手的报文(Server无法确认Client是否收到),也无法保证Client和Server之间成功互换初始序列号
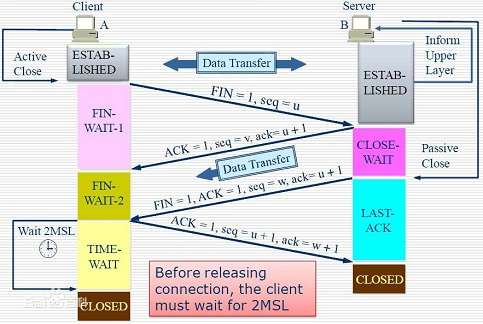
什么是四次挥手?

- 第一次挥手:Client将FIN置为1,发送一个序列号seq给Server;进入FIN_WAIT_1状态;
- 第二次挥手:Server收到FIN之后,发送一个ACK=1,acknowledge number=收到的序列号+1;进入CLOSE_WAIT状态。此时客户端已经没有要发送的数据了,但仍可以接受服务器发来的数据。
- 第三次挥手:Server将FIN置1,发送一个序列号给Client;进入LAST_ACK状态;
- 第四次挥手:Client收到服务器的FIN后,进入TIME_WAIT状态;接着将ACK置1,发送一个acknowledge number=序列号+1给服务器;服务器收到后,确认acknowledge number后,变为CLOSED状态,不再向客户端发送数据。客户端等待2*MSL(报文段最长寿命)时间后,也进入CLOSED状态。完成四次挥手。
为什么不能把服务器发送的ACK和FIN合并起来,变成三次挥手(CLOSE_WAIT状态意义是什么)?
因为服务器收到客户端断开连接的请求时,可能还有一些数据没有发完,这时先回复ACK,表示接收到了断开连接的请求。等到数据发完之后再发FIN,断开服务器到客户端的数据传送。
客户端发起断开请求FIN,客户端能控制自己不再发送数据给服务端,但是tcp是全双工的,客户端不能控制服务端发送数据过来。所以,服务端先回复ACK,表示服务端知道要断开链接了,但是还有正在发送给客户端的数据,等这些数据发完了,服务端就不再发送数据给客户端了,再发送FIN表示服务端这边也可以开始断开链接操纵了
如果第二次挥手时服务器的ACK没有送达客户端,会怎样?
客户端没有收到ACK确认,会重新发送FIN请求。
客户端TIME_WAIT状态的意义是什么?
第四次挥手时,客户端发送ACK有可能丢失,TIME_WAIT状态就是用来重发可能丢失的ACK报文。如果Server没有收到ACK,就会重发FIN,如果Client在2*MSL的时间内收到了FIN,就会重新发送ACK并再次等待2MSL,防止Server没有收到ACK而不断重发FIN
MSL(Maximum Segment Lifetime),指一个片段在网络中最大的存活时间,2MSL就是一个发送和一个回复所需的最大时间。如果直到2MSL,Client都没有再次收到FIN,那么Client推断ACK已经被成功接收,则结束TCP连接
主要有两个原因: 1)为了确保两端能完全关闭连接。 假设A服务器是主动关闭连接方,B服务器是被动方。如果没有TIME_WAIT状态,A服务器发出最后一个ACK就进入关闭状态,如果这个ACK对端没有收到,对端就不能完成关闭。对端没有收到ACK,会重发FIN,此时连接关闭,这个FIN也得不到ACK,而有TIME_WAIT,则会重发这个ACK,确保对端能正常关闭连接。
另外一个作用是,当最后一个ACK丢失时,远程连接进入LAST-ACK状态,它可以确保远程已经关闭当前TCP连接。如果没有TIME-WAIT状态,当远程仍认为这个连接是有效的,则会继续与其通讯,导致这个连接会被重新打开。当远程收到一个SYN 时,会回复一个RST包,因为这SEQ不对,那么新的连接将无法建立成功,报错终止。
 如果远程因为最后一个ACK包丢失,导致停留在LAST-ACK状态,将影响新建立具有相同四元组的TCP连接。
如果远程因为最后一个ACK包丢失,导致停留在LAST-ACK状态,将影响新建立具有相同四元组的TCP连接。
(被断开方还没CLOSED处于LAST_ACK等待主动断开方发送ACK,如果TIME_WAIT时间过短,使得主动断开方已经CLOSED了,然后主动断开方可以使用这个端口:a和IP:b,建立新的连接,发送SYN请求就会发到被动端开方还在LAST_ACK状态等待ACK没关闭的连接上,之前与主动断开方端口:a和IP:b是建立连接的,此时它们的SEQ序号是不一致的,就会导致被动断开方发送RST,此次建立连接失败。主动断开方又会重新发送建立连接请求,这样看是一种资源消耗)
2)为了确保后续的连接不会收到“脏数据” 刚才提到主动端进入TIME_WAIT后,等待2MSL后CLOSE,这里的MSL是指(maximum segment lifetime,我们内核一般是30s,2MSL就是1分钟),网络上数据包最大的生命周期。这是为了使网络上由于重传出现的old duplicate segment都消失后,才能创建参数(四元组,源IP/PORT,目标IP/PORT)相同的连接,如果等待时间不够长,又创建好了一样的连接,再收到old duplicate segment,数据就错乱了
https://developer.aliyun.com/article/745776
https://www.cnxct.com/coping-with-the-tcp-time_wait-state-on-busy-linux-servers-in-chinese-and-dont-enable-tcp_tw_recycle/
为什么是2MSL
随着时间的流逝,A发送给B的ACK报文将会有两种结局:
- ACK报文在网络中丢失;如前所述,这种情况我们不需要考虑,因为除非多次重传失败,否则AB两端的状态不会发生变化直至某一个ACK不再丢失。
- ACK报文被B接收到。我们假设A发送了ACK报文后过了一段时间t之后B才收到该ACK,则有 0 < t <= MSL。因为A并不知道它发送出去的ACK要多久对方才能收到,所以A至少要维持MSL时长的TIME_WAIT状态才能保证它的ACK从网络中消失。同时处于LAST_ACK状态的B因为收到了ACK,所以它直接就进入了CLOSED状态,而不会向网络发送任何报文。所以晃眼一看,A只需要等待1个MSL就够了,但仔细想一下其实1个MSL是不行的,因为在B收到ACK前的一刹那,B可能因为没收到ACK而重传了一个FIN报文,这个FIN报文要从网络中消失最多还需要一个MSL时长,所以A还需要多等一个MSL。
综上所述,TIME_WAIT至少需要持续2MSL时长,这2个MSL中的第一个MSL是为了等自己发出去的最后一个ACK从网络中消失,而第二MSL是为了等在对端收到ACK之前的一刹那可能重传的FIN报文从网络中消失。
(由于网络慢原因,可能在MSL时间A发的ACK才到达B,而此时B刚好重发了FIN,这个FIN实质上对A来说是没有用了,上一个FIN A收到了。要让这第二个FIN失效,也需要MSL时间,所以一共需要2MSL时间,才能让网络中旧的报文完全失效)
2MSL能够保证旧连接发送的报文,在有新的连接建立后,不会被传到新的连接的任意一端。2MSL让旧的报文都在网络中消失
2)修改系统回收参数 设置以下参数 net.ipv4.tcp_timestamps = 1 net.ipv4.tcp_tw_recycle = 1 设置该参数会带来什么问题? net.ipv4.tcp_timestamps = 1 net.ipv4.tcp_tw_recycle = 1 如果这两个参数同时开启,会校验源ip过来的包携带的timestamp是否递增,如果不是递增的话,则会导致三次握手建联不成功,具体表现为抓包的时候看到syn发出,server端不响应syn ack 通俗一些来讲就是,一个局域网有多个客户端访问您,如果有客户端的时间比别的客户端时间慢,就会建联不成功
下面再说一下linux里TIME_WAIT专有的优化参数reuse、recycle,默认也都是关闭的,这两个参数必须在timestamps打开的前提下才能生效使用:
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_tw_reuse = 1
机器作为客户端时起作用,开启后time_wait在一秒内回收
net.ipv4.tcp_tw_recycle = 0 (不要开启,现在互联网NAT结构很多,可能直接无法三次握手)
4.x后移除的tcp_tw_recycle是依赖timestamp配置,timestamp在nat下有包混乱的问题
1. 同时开启tcp_timestamp和tcp_tw_recycle会启用TCP/IP协议栈的per-host的PAWS机制
2. 经过同一NAT转换后的来自不同真实client的数据流,在服务端看来是于同一host打交道
3. 虽然经过同一NAT转化,但由于不同真实client会携带各自的timestamp值
因而无法保证整过NAT转化后的数据包携带的timestamp值严格递增
4. 当服务器的per-host PAWS机制被触发后,会丢弃timestamp值不符合递增条件的数据包
开启后在3.5*RTO(RTO时间是根据RTT时间计算而来)内回收TIME_WAIT,并60s内同一源ip主机的socket connect请求中的timestamp必须是递增的,对于服务端,同一个源ip可能会是NAT后很多机器,这些机器timestamp递增性无可保证,服务器会拒绝非递增请求连接,直接导致不能三次握手
https://www.cnxct.com/coping-with-the-tcp-time_wait-state-on-busy-linux-servers-in-chinese-and-dont-enable-tcp_tw_recycle/
recycle:对于服务端,同一个src ip,可能会是NAT后很多机器,这些机器timestamp递增性无可保证,服务器会拒绝非递增请求连接
其实TIME_WAIT状态的链接对业务程序带来的影响远小于CLOSE_WAIT一个TIME_WAIT链接会占用几K的内存资源(现在的服务器动辄上百G内存)和一个临时端口资源,一个CLOSE_WAIT链接除了占用内存资源还占用一个文件描述符;对于临时端口资源可以开启tcp_tw_reuse选项去重用,而文件描述符却不可以重用,所以CLOSE_WAIT状态的链接的危害远大于TIME_WAIT
tcp协议中处于last_ack状态的连接,如果一直收不到对方的ack,最终会进入CLOSED
上一张网上搜索的图,更好理解(侵删)
这个链接中讲述了三种情况:
下面假设:主动关闭的一端为A,被动关闭的一端为B, 根据B是否收到最后的ACK包分为两种情况
- B发送FIN,进入LAST_ACK状态,A收到这个FIN包后发送ACK包,*B收到这个ACK包*,然后进入CLOSED状态
- B发送FIN,进入LAST_ACK状态,A收到这个FIN包后发送ACK包,由于某种原因,这个ACK包丢失了,*B没有收到ACK包*,然后B等待ACK包超时,又向A发送了一个FIN包
a) 假如这个时候,A还是处于TIME_WAIT状态(也就是TIME_WAIT持续的时间在2MSL内) **A收到这个FIN包后向B发送了一个ACK包,B收到这个ACK包进入CLOSED状态
b) **假如这个时候,A已经从TIME_WAIT状态变成了CLOSED状态
A收到这个FIN包后,认为这是一个错误的连接,向B发送一个RST包,当B收到这个RST包,进入CLOSED状态 c) 假如这个时候,A挂了(假如这台机器炸掉了)【会经历超时重传,多次重传也失败,重置连接进入CLOSED】 B没有收到A的回应,那么会继续发送FIN包,也就是触发了TCP的重传机制,如果A还是没有回应,B还会继续发送FIN包,直到重传超时(至于这个时间是多长需要仔细研究),B重置这个连接,进入CLOSED状态,参考链接看这里
查询tcp各状态下的数量
netstat -ant|awk '/^tcp/ {++S[$NF]} END {for(a in S) print (a,S[a])}'
GRPC stream fail rpc error: code = Unavailable desc = transport is closing
GRPC_TRACE=all
GRPC_VERBOSITY=DEBUG
GRPC_GO_LOG_VERBOSITY_LEVEL=2
GRPC_GO_LOG_SEVERITY_LEVEL=info
What we were experiencing were random transport is closing errors on the client when making unary RPCs to our server (usually after ~5 minutes of inactivity). Most of the time, our server would not even get the request from the client, so we thought some other component in between should be causing the connections to be closed.
After some digging, we eventually found this section in the AWS network load balancer docs:
For each request that a client makes through a Network Load Balancer, the state of that connection is tracked. The connection is terminated by the target. If no data is sent through the connection by either the client or target for longer than the idle timeout, the connection is closed. If a client sends data after the idle timeout period elapses, it receives a TCP RST packet to indicate that the connection is no longer valid.
Elastic Load Balancing sets the idle timeout value to 350 seconds. You cannot modify this value. Your targets can use TCP keepalive packets to reset the idle timeout.
Immediately after seeing this, we decided to start using keepalive pings from the client. You can easily enable this on the client as a dial option (keepalive.ClientParameters) and on the server (grpc.KeepaliveEnforcementPolicy) as a server option which forces clients to comply with the keepalive policy.
Since we just use unary RPCs, we had to set PermitWithoutStream=true, so that the client sends keepalive pings while not streaming. We also made sure that the enforcement policy has a KeepaliveEnforcementPolicy.MinTime=1 * time.Minute (it has to be lower than the LB’s connection idle timeout of 350s) and the client would submit keepalive pings every 2 minutes (ClientParameters.Time=2 * time.Minute). As long as Time > MinTime, we’re good!
We applied the changes to our clients and server (as others have mentioned, the clients must comply with the server policy, otherwise you’ll have more connectivity issues) and the transport is closing issue is now totally gone, as the client will keep the connections alive.
Canal报错:batchId:73 is not the firstly:72 或 clientId:1001 batchId:50560 is not exist , please check
导致没有消息再推到kafka。简单理解:batchId不对应,使得后续的操作没法继续进行
- 第一个原因是client在ack的问题,前两个异常是client没有按照顺序ack对应的batchId
- 最后一个是ack的batchId在服务端被清理了ps. 服务端发生清理只有两个原因:
- client发起过一次rollback
- server端发生过一次instance的重启,比如scan=true时发现文件变化自动restart了
如何实现可靠数据传输
可靠传输一般包含两个方面,数据不会丢失,数据保证顺序;
- 数据不丢失依靠发送方的重传策略;
- 数据保证顺序需要通信双方维护序列号;
遵循以上的两个策略就能实现一个最基本的可靠传输协议
DNS使用UDP协议还是TCP协议
使用 TCP 协议(共 330 字节)
三次握手 — 14x3(Ethernet) + 20x3(IP) + 44 + 44 + 32(TCP) 字节
查询协议头 — 14(Ethernet) + 20(IP) + 20(TCP) 字节
响应协议头 — 14(Ethernet) + 20(IP) + 20(TCP) 字节
使用 UDP 协议(共 84 字节)
查询协议头 — 14(Ethernet) + 20(IP) + 8(UDP) 字节
响应协议头 — 14(Ethernet) + 20(IP) + 8(UDP) 字节
注1:TCP 首部的开销与具体的请求和环境有关,具体结果可能有小幅波动,其大小约为 120 字节。
注2:我们在这里计算结果的前提是 DNS 解析器只需要与一个命名服务器或者权威服务器进行通信就可以获得 DNS 响应,但是在实际场景中,DNS 解析器可能会递归地与多个命名服务器进行通信,这也加倍地放大了 TCP 协议在额外开销上的劣势。
如果 DNS 查询的请求体和响应分别是 15 和 70 字节,那么 TCP 相比于 UDP 协议会增加 ~250 字节和 ~145% 的额外开销,所以当请求体和响应的大小比较小时,通过 TCP 协议进行传输不仅需要传输更多的数据,还会消耗更多的资源,多次通信以及信息传输带来的时间成本在 DNS 查询较小时是无法被忽视的,TCP 连接带来的可靠性在 DNS 的场景中没能发挥太大的作用
UDP 协议
DNS 查询的数据包较小、机制简单;
UDP 协议的额外开销小、有着更好的性能表现;
TCP 协议
DNS 查询由于 DNSSEC 和 IPv6 的引入迅速膨胀,导致 DNS 响应经常超过 MTU 造成数据的分片和丢失,我们需要依靠更加可靠的 TCP 协议完成数据的传输;
随着 DNS 查询中包含的数据不断增加,TCP 协议头以及三次握手带来的额外开销比例逐渐降低,不再是占据总传输数据大小的主要部分
无论是选择 UDP 还是 TCP,最核心的矛盾就在于需要传输的数据包大小,如果数据包小到一定程度,UDP 协议绝对最佳的选择,但是当数据包逐渐增大直到突破 512 字节以及 MTU 1500 字节的限制时,我们也只能选择使用更可靠的 TCP 协议来传输 DNS 查询和相应
三星索引原则
- 第一颗星需要取出所有等值谓词中的列,作为索引开头的最开始的列(任意顺序);
- 第二颗星需要将 ORDER BY 列加入索引中;
-
第三颗星需要将查询语句剩余的列全部加入到索引中
- 第一颗星不只是将等值谓词的列加入索引,它的作用是减少索引片的大小以减少需要扫描的数据行;
- 第二颗星用于避免排序,减少磁盘 IO 和内存的使用;
- 第三颗星用于避免每一个索引对应的数据行都需要进行一次随机 IO 从聚集索引中读取剩余的数据
Redis启动时的数据加载
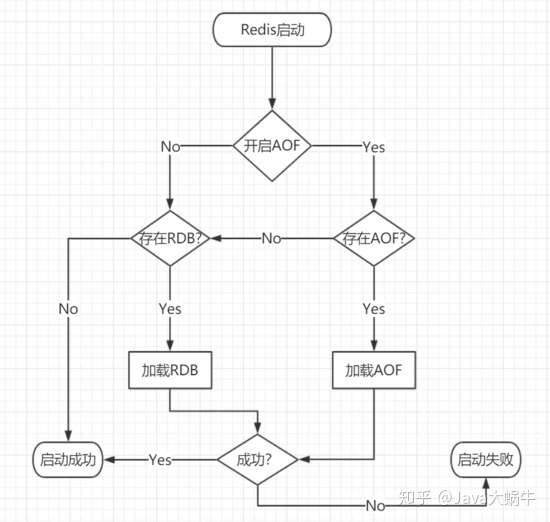
Redis启动数据加载流程:
- AOF持久化开启且存在AOF文件时,优先加载AOF文件。
- AOF关闭或者AOF文件不存在时,加载RDB文件。
- 加载AOF/RDB文件成功后,Redis启动成功。
- AOF/RDB文件存在错误时,Redis启动失败并打印错误信息
DNS原理简记
https://draveness.me/dns-coredns/
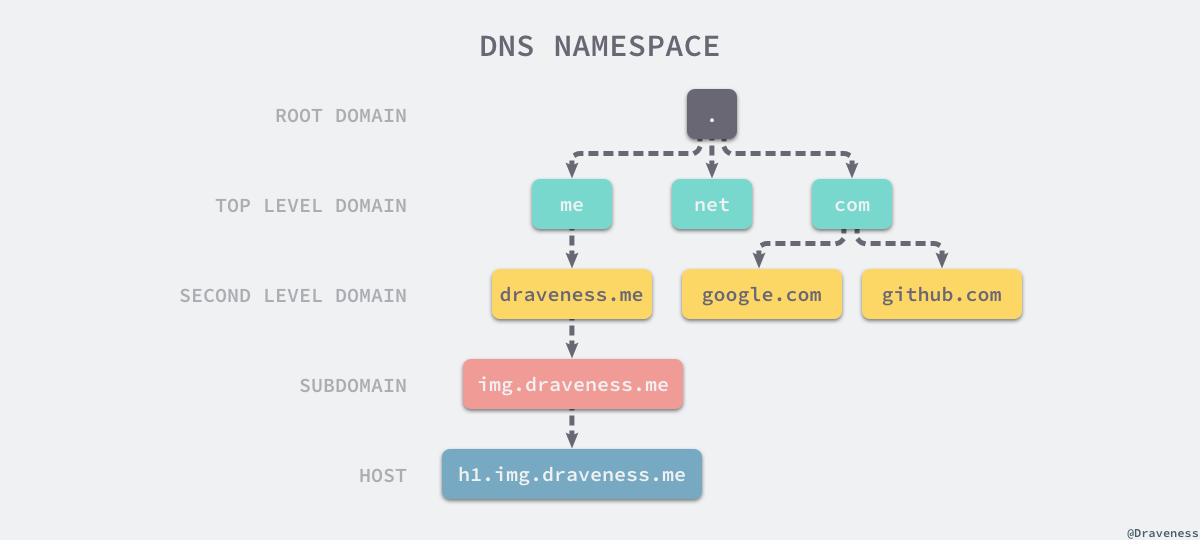
dig -t A draveness.me +trace
13 组根域名服务器发出请求获取顶级域名的地址,可以看到是.root-servers.net- 访问这些
顶级域名服务器其中的一台b2.nic.me获取权威 DNS 的服务器的地址了: - 这里的
权威 DNS 服务是在域名提供商进行配置的,当有客户端请求draveness.me域名对应的 IP 地址时,其实会使用的 DNS 服务商 DNSPod 处请求服务的 IP 地址
draveness.me. 600 IN A 34.96.168.17
draveness.me. 86400 IN NS ns3.dnsv2.com.
draveness.me. 86400 IN NS ns4.dnsv2.com.
;; Received 111 bytes from 111.30.142.15#53(ns4.dnsv2.com) in 32 ms
34.96.168.17 就是域名所指服务器的IP地址
可以了解一下根域名服务器的域名和对应的 IP 地址 https://www.iana.org/domains/root/servers
Linux IO同步函数:sync、fsync、fdatasync
http://byteliu.com/2019/03/09/Linux-IO%E5%90%8C%E6%AD%A5%E5%87%BD%E6%95%B0-sync%E3%80%81fsync%E3%80%81fdatasync/
一次磁盘IO需要的时间
根据Wikipedia的数据,当前硬盘驱动的平均寻道时间(Average seek time)大约是3~15ms,7200RPM硬盘的平均旋转延迟(Average rotational latency)大约为4ms,因此一次IO操作的耗时大约为10ms左右
使用fdatasync优化日志同步
文章开头时已提到,为了满足事务要求,数据库的日志文件是常常需要同步IO的。由于需要同步等待硬盘IO完成,所以事务的提交操作常常十分耗时,成为性能的瓶颈。 在Berkeley DB下,如果开启了AUTO_COMMIT(所有独立的写操作自动具有事务语义)并使用默认的同步级别(日志完全同步到硬盘才返回),写一条记录的耗时大约为5~10ms级别,基本和一次IO操作(10ms)的耗时相同。 我们已经知道,在同步上fsync是低效的。但是如果需要使用fdatasync减少对metadata的更新,则需要确保文件的尺寸在write前后没有发生变化。日志文件天生是追加型(append-only)的,总是在不断增大,似乎很难利用好fdatasync。
且看Berkeley DB是怎样处理日志文件的:
- 1.每个log文件固定为10MB大小,从1开始编号,名称格式为“log.%010d”
- 2.每次log文件创建时,先写文件的最后1个page,将log文件扩展为10MB大小
- 3.向log文件中追加记录时,由于文件的尺寸不发生变化,使用fdatasync可以大大优化写log的效率
- 4.如果一个log文件写满了,则新建一个log文件,也只有一次同步metadata的开销
统计词频
cat words.txt | xargs -n 1 | sort | uniq -c | sort -nr | awk '{print $2" "$1}'
B+树对比B树的优点
getconf PAGE_SIZE
4096
计算机在读写文件时会以页为单位将数据加载到内存中。
B 树能够在非叶节点中存储数据,但是这也导致在查询连续数据时可能会带来更多的随机 I/O,而 B+ 树的所有叶节点可以通过指针相互连接,能够减少顺序遍历或范围查找时产生的额外随机 I/O
B+树页方式读取出数据,适合顺序遍历减少随机I/O。B树可能在当前读取出的页中没有完全得到需要的数据,所以还需要进行随机I/O来得到其他数据
B+树在非叶子节点存储指针以及关键字信息(索引信息),这样可以最大化增加每个磁盘block存放的索引信息,比B树每层存的索引信息要多,能够降低树结构的高度。并且叶子节点是互相连接,能够减少重新IO的次数
一个高度为3的B+树可以存储千万级别的数据。B+树的高度一般都不超过5
MySQL将每个叶子节点的大小设置为一个页的整数倍,利用磁盘的预读机制,能有效减少磁盘I/O次数,提高查询效率
基本个数限制
-
在MySQL5.6.9以后的版本,一个表的最大列个数(包含虚拟列,虚拟列是MySQL5.7的新特性)为1017,在之前的版本是1000
-
一个表的最大索引数量(非主键索引)为64个
-
复合索引最多可以包括16个列,超过会报错:
ERROR 1070 (42000): Too many key parts specified; max 16 parts allowedinnodb_page_size是一个初始化数据库实例的参数,在目前的版本中(>=5.7.6),可以选择的值有4096, 8192, 16384, 32768, 65536。默认是16KB
一般越小,内存划分粒度越大,使用率越高,但是会有其他问题,就是限制了索引字段还有整行的大小。innodb引擎读取内存还有更新都是一页一页更新的,这个innodb_page_size决定了,一个基本页的大小
如果一个行数据,超过了一页的一半,那么一个页只能容纳一条记录,这样B+Tree在不理想的情况下就变成了双向链表
epoll源码结构分析
https://wenfh2020.com/2020/04/23/epoll-code/