尽量不要使用SELECT *
- 不需要的列会增加数据传输时间和网络开销。需要解析更多的对象、字段、权限、属性等内容,在SQL语句复杂,硬解析较多的情况下,会对数据库造成沉重的负担,大的文本会增加网络开销
- 对无用的打字单会增加io操作。长度超过728字节的时候,会先把超出的数据序列化到另一个地方,因此读取这条记录会增加一次io操作(MySQL InnoDB)
- 失去MySQL优化器”覆盖索引”策略优化的可能性。首先要通过辅助索引过滤数据,然后再通过聚集索引获取所有的列,这就多了一次b+树查询。原本可能只通过辅助索引即可拿到所需要的字段数据
Go http库 重用底层 TCP 连接需要注意读取完body并关闭
在结合实际的场景之后,我发现其实有的时候问题出在我们并不总是会去读取完整个http.Response 的 Body。为什么这么说呢? 在常见的 API 开发的业务逻辑中,我们会定义一个 JSON 的对象来反序列化 http.Response 的 Body,但是通常在反序列化这个回复之前,我们会做一些 http 的 StatusCode 检查,比如当 StatusCode 为 200 的时候,我们才去读取 http.Response 的 Body,如果不是 200,我们就直接返回一个包装好的错误。比如下面的模式:
resp, err := http.Get("http://www.example.com")
if err != nil {
return err
}
defer resp.Body.Close()
if resp.StatusCode == http.StatusOK {
var apiRet APIRet
decoder := json.NewDecoder(resp.Body)
err := decoder.Decode(&apiRet)
// ...
}
如果代码是按照上面的这种方式写的话,那么在请求异常的时候,会导致大量的底层 TCP 无法重用,所以我们稍微改进下就可以了。
resp, err := http.Get("http://www.example.com")
if err != nil {
return err
}
defer resp.Body.Close()
if resp.StatusCode == http.StatusOK {
var apiRet APIRet
decoder := json.NewDecoder(resp.Body)
err := decoder.Decode(&apiRet)
// ...
}else{
io.Copy(ioutil.Discard, resp.Body) // 关键的一步,帮我们读取完body
// ...
}
我们通过直接将 http.Response 的 Body 丢弃掉就可以了。
Kafka 的consumer offset数据过大容易导致的启动加载问题
Kafka内部会有topic: __consumer_offsets, 这个topic存储offset信息。当__consumer_offsets分区数据巨大,且分布不均,Kafka启动或重启时,加载__consumer_offsets数据就会非常的慢,很有可能导致启动超时,从而Kafka服务没法启动。
修改__consumer_offsets的cleanup.policy=delete,保留时间为15天,减少topic保存的数据量,减少Kafka加载压力
Kafka在合ZooKeeper连接时,如果由于网络等原因,可能会导致没法连接上ZooKeeper而发生重启。
使用canal和kafka进行数据库同步
为每个表配置分区key,每个表对应一个partition,以保证按照binlog数据顺序进行同步。是的这样会牺牲并发性。
如何为Kafka集群选择合适的Partitions数量
https://blog.csdn.net/oDaiLiDong/article/details/52571901?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
epoll存在惊群效应
惊群效应会影响:多进程/线程的唤醒,涉及到的一个问题是上下文切换问题。频繁的上下文切换带来的一个问题是数据将频繁的在寄存器与运行队列中流转。极端情况下,时间更多的消耗在进程/线程的调度上,而不是执行。 accept是队列方式处理,解决了惊群效应,accept确实应该只能被一个进程调用成功,但是epoll的情况就比较复杂,epoll监听的文件描述符, 除了可能后续被accept调用外,还可能是其他网络IO事件的监听对象,那其他网络IO是否只能由一个进程处理我们是不得知的。 所以linux对epoll并没有就惊群效应做修复,而是放之,让用户层自己做处理。比如:Nginx accept mutex锁,在请求来的时候只有获得accept mutex锁的worker才会唤醒去处理这个请求 Nginx 主体的思想是通过锁的形式来处理这样问题。我们每个进程在监听 FD 事件之前,我们先要通过 ngx_trylock_accept_mutex 去获取一个全局的锁。如果拿锁成功,那么则开始通过 ngx_process_events 尝试去处理事件。如果拿锁失败,则放弃本次操作。所以从某种意义上来讲,对于某一个 FD ,Nginx 同时只有一个 Worker 来处理 FD 上的事件。从而避免惊群。
epoll惊群问题在内核版本要在 Linux Kernel 4.5通过增加一个 EPOLLEXCLUSIVE 标志位,进行了优化,但是只保证唤醒的进程数小于等于我们开启的进程数,而不是直接唤醒所有进程,也不是只保证唤醒一个进程。很多时候我们还是要依靠应用层自身的设计来解决
https://zhuanlan.zhihu.com/p/60966989
经典云计算架构 IaaS、PaaS、SaaS
IaaS基础设施即服务:IaaS层为基础设施运维人员服务,提供计算、存储、网络及其其他基础资源,云平台使用者可以在上面部署和运行包括操作系统和应用程序在内的任意软件,无需为基础设施的管理而分心 Paas平台即服务:PaaS层为应用开发人员服务,提供支撑应用运行所需要的软件运行时环境、相关工具服务,入数据库服务、日志服务、监控服务等,让应用开发者可以专注于核心业务的开发 SaaS软件即服务:SaaS层为一般用户服务,提供了一套完整可用的软件系统,让一般用户无需关注技术细节,只需要通过浏览器、应用客户端等方式就能使用部署在云上的应用服务
Kafka消费失败补偿方案
- 申请一个新的kafka topic作为重试队列,步骤如下:
- 创建一个topic作为重试topic用于接受等待重试的消息
- 普通topic消费者给待重试的消息设置下一次的消费事件后发送到重试topic
- 从重试topic获取待重试消息储存到redis的zset中,并以下一次消费时间排序
- 定时任务从redis获取到达消费事件的消息,并把消息发送到对应的topic,同一个消息重试次数过多则不再重试
推文简单主页设计思路
大多数用户发的推文会被扇出写入其所有粉丝主页时间线缓存中。(如消息队列推送给每个粉丝的主页中)但是少数拥有海量粉丝的用户,即大V,会被排除在外。当用户读取主页时间线时,分别获取该用户所关注的每位大V的推文,再与用户的主页时间线缓存合并。这种混合方法能始终如一地提供良好的性能
GRPC status包使用detail遇到的问题
涉及的包 "google.golang.org/grpc/status"
定义了一个response.proto
message Response {
int32 Code = 1;
string Message = 2;
}
继续封装了一个包resp
type Response struct {
*pbresp.Response // protobuf的Response
Data interface{} // 附加数据
msgArgs []interface{} // 为Message格式化字符串提供参数
omitData bool // 是否忽略Data,当为True时Marshal数据中将不会包含Data字段
}
这个Response满足protobuf,所以可以这样
func NewGRPCState(code codes.Code, r *resp.Response) *status.Status {
state := status.New(code, r.GetMessage())
state, _ = state.WithDetails(r)
return state
}
是的,在WithDetails的时候是不会报错的,但是在解析的时候失败了,并没有得到想要的结果
因为,传入WithDetails的r *resp.Response没有实现 proto.RegisterType()方法
涉及到的三个map没有对应的数据,对应的key是nil的:
导致在Details方法的时候,没能正确反序列化的interface值,而是error,从而没有得到想要的结果
var (
protoTypedNils = make(map[string]Message) // a map from proto names to typed nil pointers
protoMapTypes = make(map[string]reflect.Type) // a map from proto names to map types
revProtoTypes = make(map[reflect.Type]string)
)
func (s *Status) Details() []interface{} {
if s == nil || s.s == nil {
return nil
}
details := make([]interface{}, 0, len(s.s.Details))
for _, any := range s.s.Details {
detail := &ptypes.DynamicAny{}
if err := ptypes.UnmarshalAny(any, detail); err != nil { // 1. 这里进入反序列化
details = append(details, err) // 2. 报错会将错误加入到details
continue
}
details = append(details, detail.Message)
}
return details
}
// pb can be a proto.Message, or a *DynamicAny.
func UnmarshalAny(any *any.Any, pb proto.Message) error {
if d, ok := pb.(*DynamicAny); ok {
if d.Message == nil {
var err error
d.Message, err = Empty(any) // 3. 会进行Empty方法操作
if err != nil {
return err
}
}
return UnmarshalAny(any, d.Message)
}
aname, err := AnyMessageName(any)
if err != nil {
return err
}
mname := proto.MessageName(pb)
if aname != mname {
return fmt.Errorf("mismatched message type: got %q want %q", aname, mname)
}
return proto.Unmarshal(any.Value, pb)
}
// Empty returns a new proto.Message of the type specified in a
// google.protobuf.Any message. It returns an error if corresponding message
// type isn't linked in.
func Empty(any *any.Any) (proto.Message, error) {
aname, err := AnyMessageName(any)
if err != nil {
return nil, err
}
t := proto.MessageType(aname) // 4.MessageType方法查找aname的key
if t == nil {
return nil, fmt.Errorf("any: message type %q isn't linked in", aname) // 6.t是nil报错返回,append到了details
}
return reflect.New(t.Elem()).Interface().(proto.Message), nil
}
// MessageType returns the message type (pointer to struct) for a named message.
// The type is not guaranteed to implement proto.Message if the name refers to a
// map entry.
func MessageType(name string) reflect.Type {
if t, ok := protoTypedNils[name]; ok {
return reflect.TypeOf(t)
}
return protoMapTypes[name] // 5. 没有调用proto.RegisterType(),protoMapTypes map中没有对应的name的值,返回的是nil从而导致报错了
}
而protobuf 的Response是有调用这个方法的:
func init() {
proto.RegisterType((*Response)(nil), "pbresp.v1.Response")
}
所以,我们需要传protobuf 的Response
修改为:
func NewGRPCState(code codes.Code, r *resp.Response) *status.Status {
state := status.New(code, r.GetMessage())
state, _ = state.WithDetails(r.Response) // 传的是*pbresp.Response
return state
}
func ParseGRPCStateResponse(state *status.Status) (*pbresp.Response, error) {
details := state.Details()
rOK := &pbresp.Response{
RetCode: 0,
Message: "OK",
}
if len(details) == 0 {
return rOK, nil
}
res, ok := details[0].(*pbresp.Response)
if !ok {
ugin.LOGGER.Error("grpc status detail type error")
return nil, errors.New("grpc status detail type error")
}
return res, nil
}
最简单的有序map实现思考
type OrderedMap struct {
keys []string // key数组
values map[string]interface{} // 内部map
}
插入key时,将key加到keys的末尾
删除key时,也在keys数组中将其删除
func (o *OrderedMap) Delete(key string) {
_, ok := o.values[key]
if !ok {
return
}
// remove from keys
for i, k := range o.keys {
if k == key {
o.keys = append(o.keys[:i], o.keys[i+1:]...) // 去除当前i的key 这一步时间复杂度很高
break
}
}
// remove from values
delete(o.values, key)
}
只有当要顺序遍历OrderedMap时,先对keys数组进行排序,然后再按keys排序的结果进行遍历得到key,再去values map中得到对应值,这样每次写入的时候是不用排序的
另一种方案,keys数组按照二叉搜索树的方式存储(二叉堆),这样写入会是log(n),遍历的时候,对keys进行中序遍历log(n),能得到排序的key 但是,二叉搜索树有可能退化成链表,则时间复杂度变成O(n)
或者用链表,链表就是插入或删除的时候,需要先遍历到合适的位置 如果链表每个node的指针有存在map中,则删除的时候不用先遍历查找到该元素在链表的位置,而是直接用缓存的node节点指针 进行操作
func (om *OrderedMap) Delete(key interface{}) {
_, ok := om.store[key]
if ok {
delete(om.store, key)
}
root, rootFound := om.mapper[key]
if rootFound {
prev := root.Prev
next := root.Next
prev.Next = next
next.Prev = prev
delete(om.mapper, key)
}
}
遇到go get 失败的诡异情况
go get go mod download 都失败,而go get 老版本提示有cache,到指定目录删除了cache,然后老版本可以get下来了,新版本也可以了。 解决方法:删除cache中的缓存
报错信息:
git fetch -f origin refs/heads/*:refs/heads/* refs/tags/*:refs/tags/* in /Users/pathbox/go/pkg/mod/cache/vcs/1bff0296f0b3f48e2a9eb3d733cd696414472b983aade012848e0ba698a2efd8: exit status 128:
error: refs/tags/v0.2.0 does not point to a valid object!
2>&1 | tee 将stdout stderr 输入到指定文件
program [arguments…] 2>&1 | tee outfile go run main.go 2>&1 | tee info.log
| program [arguments…] 2>&1 | tee -a outfile 追加方式 |
nohup ./iam_migration 2>&1 > iam_migration_no_gray_20210403-1.log &
边缘触发和水平触发
水平触发(level-triggered,也被称为条件触发)LT: 只要满足条件,就触发一个事件(只要有数据没有被获取,内核就不断通知你)
边缘触发(edge-triggered)ET: 每当状态变化时,触发一个事件
“举个读socket的例子,假定经过长时间的沉默后,现在来了100个字节,这时无论边缘触发和条件触发都会产生一个read notification通知应用程序可读。应用程序读了50个字节,然后重新调用api等待io事件。这时条件触发水平触发的api会因为还有50个字节可读从 而立即返回用户一个read notification。而边缘触发的api会因为可读这个状态没有发生变化而陷入长期等待。 因此在使用边缘触发的api时,要注意每次都要读到socket返回EWOULDBLOCK为止,否则这个socket就算废了。而使用条件触发水平触发的api 时,如果应用程序不需要写就不要关注socket可写的事件,否则就会无限次的立即返回一个write ready notification。大家常用的select就是属于条件触水平触发发这一类,长期关注socket写事件会出现CPU 100%的毛病
水平触发的主要特点是,如果用户在监听epoll事件,当内核有事件的时候,会拷贝给用户态事件,但是如果用户只处理了一次,那么剩下没有处理的会在下一次epoll_wait再次返回该事件。 这样如果用户永远不处理这个事件,就导致每次都会有该事件从内核到用户的拷贝,耗费性能,但是水平触发相对安全,最起码事件不会丢掉,除非用户处理完毕。 边缘触发,相对跟水平触发相反,当内核有事件到达, 只会通知用户一次,至于用户处理还是不处理,以后将不会再通知。这样减少了拷贝过程,增加了性能,但是相对来说,如果用户马虎忘记处理,将会产生事件丢的情况
level-triggered and edge-triggered
这两种底层的事件通知机制通常被称为水平触发和边沿触发,真是翻译的词不达意,如果我来翻译,我会翻译成:状态持续通知和状态变化通知。
这两个概念来自电路,triggered代表电路激活,也就是有事件通知给程序,level-triggered表示只要有IO操作可以进行比如某个文件描述符有数据可读,每次调用epoll_wait都会返回以通知程序可以进行IO操作,edge-triggered表示只有在文件描述符状态发生变化时,调用epoll_wait才会返回,如果第一次没有全部读完该文件描述符的数据而且没有新数据写入,再次调用epoll_wait都不会有通知给到程序,因为文件描述符的状态没有变化
epoll中的触发模式有两种,边缘触发和水平触发,默认情况下使用的是水平触发。
边缘触发(ET)的意思是当电平出现变化的时候才触发事件,如果设置了边缘触发,执行epoll_wait时,内核检测到数据到达后立马返回到应用层。但是这仅仅只返回这一次,如果缓冲区中的数据没有读取完,再次执行epoll_wait时不会继续触发,需要下一次来数据了才能触发。也就是说,一次数据不会重复发送到应用层,不管你是否读完了。
而水平触发(LT)的意思是只要存在高电平就一直触发事件,执行epoll_wait时,只要检测到有数据就返回。如果缓冲区中存在没有读完的数据,下一次执行epoll_wait还会继续触发事件,无需等到下一次数据来。
两者的触发时间点:
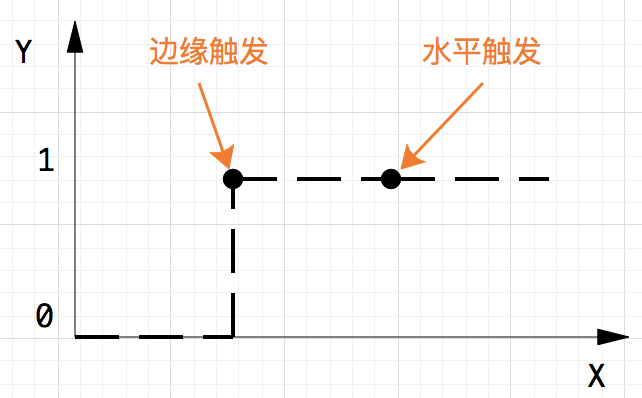
相比之下,ET的效率高于LT模式,因为产生的事件数更少,可以减少内核往应用层空间复制数据的次数。在进行高性能网络编程的时候,往往都是选择非阻塞IO+ET触发模式,这种模式下可以做到想读数据的时候就读,不想读就不读。同时,读不到也不阻塞,大大增加了程序的灵活性。而不是说不管是否想读数据,都强制要求读。
项目中使用ET模式时遇到了一个问题:我们开发了一个socks5代理程序,可以用来代理上网。正常的程序代理都没有问题,就是网页中的实时视频使用代理会出现延时,延时能达到5-10毫秒。最后查了很久之后发现是ET触发模式导致的, 发送数据的时候内核不会立马发出去,改成LT模式之后就好了。(LT会尽力将数据处理完,而ET需要有事件驱动一次,触发一次,对于延迟敏感的场景LT就更合适了)
https://mp.weixin.qq.com/s?__biz=MzI1MzYzMTI2Ng==&mid=2247483708&idx=1&sn=593e71668a153e2136f35f54c36bb383&scene=21#wechat_redirect
golang hash的扩容
哈希在存储元素过多时会触发扩容操作,每次都会将桶的数量翻倍,整个扩容过程并不是原子的,而是通过 runtime.growWork 增量触发的,在扩容期间访问哈希表时会使用旧桶,向哈希表写入数据时会触发旧桶元素的分流;除了这种正常的扩容之外,为了解决大量写入、删除造成的内存泄漏问题,哈希引入了 sameSizeGrow 这一机制,在出现较多溢出桶时会对哈希进行『内存整理』减少对空间的占用